Building Automation for Fraud Detection Using OpenSearch and Terraform
March 14, 2023Organizations that interface with online payments are continuously monitoring and guarding against fraudulent activity. Transactional fraud usually presents itself as discrete data points, making it challenging to identify multiple actors involved in the same group of transactions. Even a single actor operating over a period of time can be hard to detect. Visibility is key to prevent fraud incidents from occurring and to give meaningful knowledge of the activities within your environment to data, security, and operations engineers.
Understanding the connections between individual data points can reduce the time for customers to detect and prevent fraud. You can use a graph database to store transaction information along with the relationships between individual data points. Analyzing those relationships through a graph database can uncover patterns difficult to identify with relational tables. Fraud graphs enable customers to find common patterns between transactions, such as phone numbers, locations, and origin and destination accounts. Additionally, combining fraud graphs with full text search provides additional benefits as it can simplify analysis and integration with existing applications.
In our solution, financial analysts can upload graph data, which gets automatically ingested into the Amazon Neptune graph database service and replicated into Amazon OpenSearch Service for analysis. Data ingestion is automated with Amazon Simple Storage Service (Amazon S3) and Amazon Simple Queue Service (Amazon SQS) integration. We do data replication through AWS Lambda functions and AWS Step Functions for orchestration. The design is using open source tools and AWS Managed Services to build resources and is available in this https://github.com/aws-samples/neptune-fraud-detection-with-opensearch GitHub repository under an MIT-0 license. You will use Terraform and Docker to deploy the architecture, and will be able to send search requests to the system to explore the dataset.
Solution overview
This solution takes advantage of native integration between AWS services for scalability and performance, as well as the Neptune-to-OpenSearch Service replication pattern described in Neptune’s official documentation.

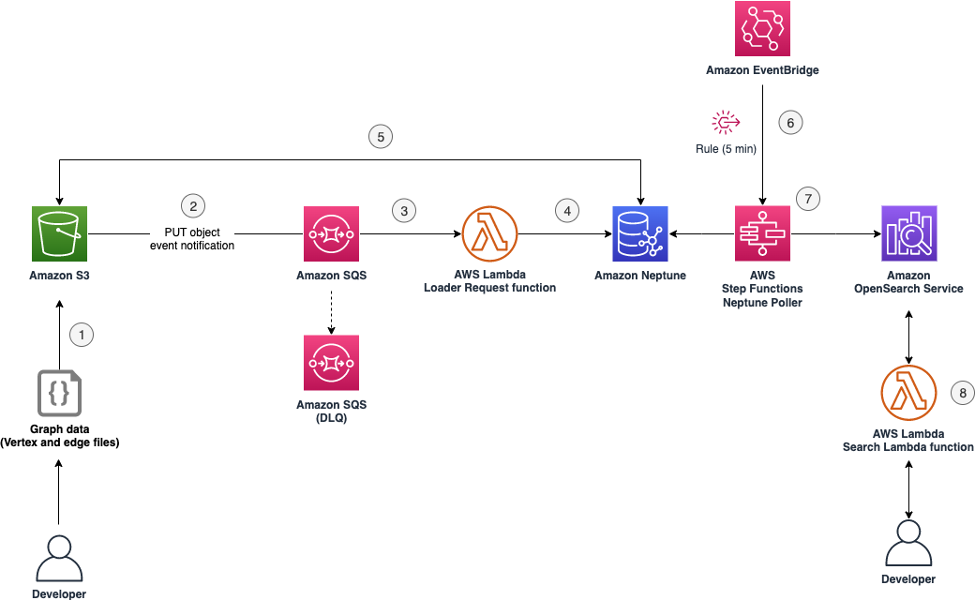
Figure 1 An architectural diagram that illustrates the infrastructure state and workflow as defined in the Terraform templates.
The process for this solution consists of the following steps, also shown in the architecture diagram here:
- Financial analyst uploads graph data files to an Amazon S3 bucket.
Note: The data files are in a Gremlin load data format (CSV) and can include vertex files and edge files.
- The action of the upload invokes a PUT object event notification with a destination set to an Amazon SQS queue.
- The SQS queue is configured as an AWS Lambda event source, which invokes a Lambda function.
- This Lambda function sends an HTTP request to an Amazon Neptune database to load data stored in an S3 bucket.
- The Neptune database reads data from the S3 endpoint defined in the Lambda request and loads the data into the graph database.
- An Amazon EventBridge rule is scheduled to run every 5 minutes. This rule targets an AWS Step Functions state machine to create a new execution.
- The Neptune Poller step function (state machine) replicates the data in the Neptune database to an OpenSearch Service cluster.
Note: The Neptune Poller step function is responsible for continually syncing new data after the initial data upload using Neptune Streams. - User can access the replicated data from the Neptune database with Amazon OpenSearch Service.
Note: A Lambda function is invoked to send a search request or query to an OpenSearch Service endpoint to get results.
Prerequisites
To implement this solution, you must have the following prerequisites:
- An AWS account with local credentials is configured. For more information, check the documentation on configuration and credential file settings.
- The latest version of the AWS Command Line Interface (AWS CLI).
- An IAM user with Git credentials.
- A Git client to clone the source code provided.
- A Bash shell.
- Docker installed on your localhost.
- Terraform installed on your localhost.
Deploying the Terraform templates
The solution is available in this GitHub repository with the following structure:
- data: Contains a sample dataset to be used with the solution for demonstration purposes. Information on fictional transactions, identities and devices is represented in files within the nodes/ folder, and relationships between them are represented in files in the edges/ folder.
- terraform: This folder contains the Terraform modules to deploy the solution.
- documents: This folder contains the architecture diagram image file of the solution.
- Create a local directory called NeptuneOpenSearchDemo and clone the source code repository:
mkdir -p $HOME/NeptuneOpenSearchDemo
cd $HOME/NeptuneOpenSearchDemo
git clone https://github.com/aws-samples/neptune-fraud-detection-with-opensearch.git
- Change directory into the Terraform directory:
cd $HOME/NeptuneOpenSearchDemo neptune-fraud-detection-with-opensearch /terraform
- Make sure that the Docker daemon is running:
docker info
If the previous command outputs an error that is unable to connect to the Docker daemon, start Docker and run the command again.
- Initialize the Terraform folder to install required providers:
terraform init
The solution is deployed on us-west-2 by default. The user can change this behavior by modifying the variable “region” in variables.tf file.
- Deploy the AWS services:
terraform apply -auto-approve
Note: Deployment will take around 30 minutes due to the time necessary to provision the Neptune and OpenSearch Service clusters.
- To retrieve the name of the S3 bucket to upload data to:
aws s3 ls | grep "neptunestream-loader.*\d$"
- Upload node data to the S3 bucket obtained in the previous step:
aws s3 cp $HOME/NeptuneOpenSearchDemo/neptune-fraud-detection-with-opensearch /data s3:// neptunestream-loader-us-west-2-123456789012 --recursive
Note: This is a sample dataset for demonstration purposes only created from the IEEE-CIS Fraud Detection dataset.
Test the solution
After the solution is deployed and the dataset is uploaded to S3, the dataset can be retrieved and explored through a Lambda function that sends a search request to the OpenSearch Service cluster.
- Confirm the Lambda function that sends a request to OpenSearch was deployed correctly:
aws lambda get-function --function-name NeptuneStreamOpenSearchRequestLambda –-query ‘Configuration.[FunctionName, State]’
- Invoke the Lambda function to see all records present in OpenSearch that are added from Neptune:
aws lambda invoke --function-name NeptuneStreamOpenSearchRequestLambda response.json
The results of the Lambda invocation are stored in the response.json file. This file contains the total number of records in the cluster and all records ingested up to that point. The solution stores records in the index amazon_neptune. An example of a node with device information looks like this:
Cleaning up
To avoid incurring future charges, clean up the resources deployed in the solution:
terraform destroy –auto-approve
The command will output information on resources being destroyed.
Destroy complete! Resources: 101 destroyed.
Conclusion
Fraud graphs are complementary to other techniques organizations can use to detect and prevent fraud. The solution presented in this blog post reduces the time financial analysts would take to access transactional data by automating data ingestion and replication. It also improves performance for systems with growing volumes of data when compared to executing a large number of insert statements or other API calls.
