How SmugMug Increased Data Modeling Productivity with Amazon Q Developer
November 29, 2024This post is co-written with Dr. Geoff Ryder, Manager, at SmugMug.
Introduction
SmugMug operates two very large online photo platforms: SmugMug and Flickr. These platforms enable more than 100 million customers to safely store, search, share, and sell tens of billions of photos every day. However, the data science and engineering team at SmugMug and Flickr often faces complex data modeling challenges that require significant time to resolve.
These challenges arise due to several factors. First, the team has to contend with diverse datasets from different sources. Additionally, the database schema and tables are highly complex, and the team needs to quickly understand application (PHP) code and database table structures in order to generate the necessary complex database queries. Specifically, SmugMug uses Amazon Redshift as its cloud data warehouse to analyze patterns in petabyte-scale data stored in Amazon S3, as well as transactional data in Amazon Aurora and Amazon DynamoDB. This allows them to generate dozens of business reports daily.
However, the complexity increases further as many database tables also need to be imported from third-party organizations into Amazon Redshift, where they are joined with SmugMug and Flickr’s internal tables. In extreme cases, properly modeling all these database tables and handling issues like granularity, cardinality, timestamps and missing data could take years – an impractical timeline for the business. We are excited to walk through SmugMug’s data modeling use cases and how SmugMug uses Amazon Q Developer to improve the data science and engineering team’s productivity.
Discovering Amazon Q Developer
SmugMug was one of the first customers to pilot Amazon Q Developer (previously Amazon CodeWhisperer), the most capable AI-powered assistant for software development that re-imagines the experience across the entire software development lifecycle, making it easier and faster to build, secure, manage, optimize, operate, and transform applications on AWS. There are multiple Amazon Q Developer use cases at SmugMug and Flickr, such as using Amazon Q Developer agent (/dev) for software development (i.e. generating implementation plans and the accompanying code), generating inline code suggestions, asking Amazon Q Developer in chat about AWS services and best practices, and analyzing AWS usage and costs for Cloud Financial Management (CFM) needs. For the data science and engineering team specifically, the key feature is chatting with Amazon Q Developer in integrated development environments (IDEs) like Intellij DataGrip. The data analysts and data scientists at SmugMug and Flickr ask questions in Amazon Q Developer chat to analyze database schemas, generate data model diagrams from DDL (Data Definition Language) statements, convert queries between languages, automatically generate complex database queries for data analysis, generate code to validate table contents, and predict trends using ML (Machine Learning).
Implementing Amazon Q Developer
To solve the data modeling challenges SmugMug faced, the team collaborated closely with their AWS Account Team, AWS Professional Services, and the Amazon Q Developer service team to create and test a data modeling assistant solution using Amazon Q Developer.
As a first step, the data modeler needs to bring the right metadata to bear. For simpler cases, the commands “show view myschema.v” or “show table myschema.t“ retrieve DDL schema information about the specified view or table from Amazon Redshift into the IDE console.
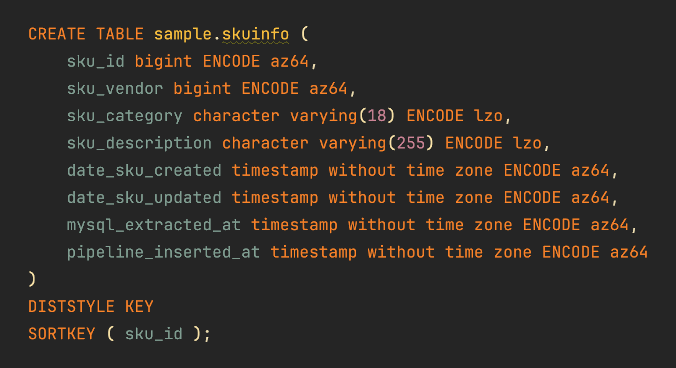
Here’s an example using simulated data for a hypothetical company. For this typical company that handles orders for products, the result of typing “show table sample.orderinfo” and “show table sample.skuinfo” might be:


This DDL text is now in the open tab. By selecting the text to highlight it, that DDL text becomes part of the context that Amazon Q Developer sees. The modeler can start asking questions about them in the Amazon Q Developer chat window in the IDE.

In complex scenarios, establishing the correct modeling context requires a combination of schema information, legacy SQL, application source code in various programming languages, sample values, and natural language documentation. Amazon Q Developer addresses this by creating a local index of relevant files and content. When a question is asked using @workspace, this index is consulted to identify and include pertinent sections of code and information in the request. (See this article for additional details on workspace). The prompt plays a crucial role in measuring similarity, so providing comprehensive context within it is essential. To optimize this process, the IDE settings feature a tunable workspace index function, allowing for enhanced performance in identifying and incorporating relevant context.

Workspace Index Settings
By adopting Amazon Q Developer as a team, we are able to jointly develop and share proprietary prompt text to address the four steps in our modeling process, as follows.
Step 1. Define the goal for the data modeling project
From prior knowledge, sketch a high-level goal for a data model. Gather the data for it manually, or by e.g. querying a vector database and adding its documents to the project.
For this example, we choose as the goal to compute aggregated metrics from a new table or view composed of two existing tables, sample.orderinfo and sample.skuinfo. These contain simulated data about product sales that are common to many companies. The order table is in the style of a fact table that logs customer orders, and the stock keeping unit (SKU) table is a dimension table that provides additional data points of interest about each order. The order and SKU information need to be combined by a join operation before we can compute the metrics. We would like Amazon Q Developer to tell us how to write that SQL join statement.
Step 2. Conduct an exploratory analysis and generate candidates
Next, prompt Amazon Q Developer for candidate foreign keys to join the tables, and for SQL code to execute those joins. Generate an entity-relationship diagram (ERD) as a visual aid. Prompts do not have to be complicated. For example:
@workspace What columns of database tables sample.orderinfo and sample.skuinfo would be best to join the two tables? Provide SQL code for the join. Draw an entity relationship diagram that shows the joins between the two tables, and includes only the fields involved in the join. Add a crow's foot cardinality marker to indicate a 1:many relationship, and add it next to the high cardinality table.


Each time tables are joined together, new aggregated metrics become available to drive business insights. Now, for instance, we can find the top selling SKUs in October thanks to our results:

Sometimes we need to look at code written in languages other than SQL to complete the data model. For example, the names of some vendors this company works with happen to appear in application PHP code as human readable strings, but are saved in the application database as numbers. The analytics data staged in Redshift only contain the numbers. So, we pull a copy of the PHP text file into @workspace, and ask Amazon Q Developer to translate the relevant string-integer mappings into a SQL case statement.

PHP Switch statement showing the mapping of Vendor Ids to String Names.
I am a Redshift database administrator and I am working on a data modeling problem. I would like to write SQL statements to join tables sample.orderinfo and sample.skuinfo. Please write that SQL to join the two tables. Also, I would like to write a SQL case statement to recover all string values defined in PHP that are represented as integer values in the database table.
The output of that prompt is shown below.

Amazon Q Developer automatically detected the PHP switch case statement, converted to SQL, and added it to the final query. Many other programming languages are supported, and modelers should try this technique with other kinds of source code. Note that data scientists and analysts may not know where to look in complex application code for these details, so this discovery-plus-code translation step is a net new benefit to our company that is only possible thanks to Amazon Q Developer.
Step 3. Create code to test the analysis
Now we request SQL source code for a battery of small test queries. These can return cardinality, grain, arithmetic, and null count results.
Please write a short SQL test to compute counts of the key fields that are used in the joins, which will verify the cardinality assignments indicated in the entity relationship diagram above. The SQL test should compare distinct counts to total counts and null counts when it verifies the cardinality.

Step 4. Validate the results of the analysis
Run the test queries to see if the candidate solution from step 2 meets our goals. The “Insert at cursor” button at the bottom of the response is handy for this. The data modeler can easily spot an error in the join logic and ERD from inspecting the output of the test query. (Or, if it’s hard to interpret the results, keep making the test queries simpler.) If errors arise from the AI misinterpreting or miscalculating a result, or from a vaguely worded prompt, simply adjust the prompt in step 2 to fix the known errors, and repeat steps 2 – 4.

After a few iterations, taking from seconds to at most tens of minutes each, the modeling errors have been worked out and we arrive at a valid production query.
Key Benefits and Results
With this Amazon Q Developer powered solution and iterative approach, SmugMug has achieved highly accurate data modeling results across numerous database tables. Once the correct modeling configuration is established, various useful outputs may become available.
We already described production SQL, unit tests, and ERDs for documentation. By the end of the process, because Amazon Q Developer has a good understanding of the data it just modeled in its chat history, it will also generate useful Python machine learning programs to predict business trends. Here is a prompt for that, and a partial screenshot of the Python output:
Please write Python code to implement a linear regression that predicts the quantity_ordered value based on other fields in the data set. Choose predictor variables that are less likely to cause multi-collinearity problems.

This only shows the model training step, but the full response included all library imports, a Redshift query, feature engineering steps, ML performance metrics, and code for plotting the metrics. And the AI can produce other types of predictive models. For example, you can try:
Please write Python code to implement an XGBoost model that predicts the quantity_ordered value based on other fields in the data set.
Ultimately, the solution has improved team productivity for both existing and new team members, while maintaining legacy knowledge needed to onboard new team members more efficiently. Key benefits include:
- Reducing SmugMug data analyst and scientist’s time spent on data modeling tasks from days to hours, allowing them to reallocate this time to other high-priority projects.
- Automating the generation of BI documentation and predictive ML, also saving crucial time.
- Providing net new value by translating application code constant definitions into SQL. Due to organizational boundaries, we would not have achieved this without an assist from the AI.
Future Plans and Expansion
SmugMug conducted the initial data modeling use case testing with over a dozen data science team members and analysts. We are moving on to analyze more complex tables and data schemas, and generating Python code in Amazon SageMaker for ML tasks like data preparation, training, inference, and MLOps. From our experience, Amazon Q Developer has become a preferred internal tool for development that has a data modeling component, and its use continues to expand to different groups around the company.
For SmugMug’s data modeling projects, we continue to enhance the four-step process described above. In order to gather the most relevant context to solve a problem, we build vector database collections to pull from schemas, older SQL code, application source code, BI tool content, and curated documentation. The vector search operation surfaces the right content, and spares data modelers from manually searching in different code archives. We use ChromaDB to do the searches, and bring the results from ChromaDB into the workspace as additional files.
Conclusion
Using Amazon Q Developer for data modeling use cases, SmugMug has managed to increase data science and engineering team productivity by up to 100% when compared to prior workflows. To explore how Amazon Q Developer can benefit your organization, get started here. If you have questions or suggestions, please leave a comment below.
About the Authors
