Adding CDK Constructs to the AWS Analytics Reference Architecture
November 21, 2022In 2021, we released the AWS Analytics Reference Architecture, a new AWS Cloud Development Kit (AWS CDK) application end-to-end example, as open source (docs are CC-BY-SA 4.0 International, sample code is MIT-0). It shows how our customers can use the available AWS products and features to implement well-architected analytics solutions. It also regroups AWS best practices for designing, implementing and operating analytics solutions through different purpose-built patterns. Altogether, the AWS Analytics Reference Architecture answers common requirements and solves customer challenges.
In 2022, we extended the scope of this project with AWS CDK constructs to provide more granular and reusable examples. This project is now composed of:
- Reusable core components exposed in an AWS CDK library currently available in Typescript and Python. This library contains the AWS CDK constructs that can be used to quickly provision prepackaged analytics solutions.
- Reference architectures consuming the reusable components in AWS CDK applications, and demonstrating end-to-end examples in a business context. Currently, only the AWS native reference architecture is available but others will follow.
In this blog post, we will first show how to consume the core library to quickly provision analytics solutions using CDK Constructs and experiment with AWS analytics products.
Building solutions with the Core Library
To illustrate how to use the core components, let’s see how we can quickly build a Data Lake, a central piece for most analytics projects. The storage layer is implemented with the DataLakeStorage CDK construct relying on Amazon Simple Storage Service (Amazon S3), a durable, scalable and cost-effective object storage service. The query layer is implemented with the AthenaDemoSetup construct using Amazon Athena, an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. With regard to the data catalog, it‘s implemented with the DataLakeCatalog construct using AWS Glue Data Catalog.
Before getting started, please make sure to follow the instructions available here for setting up the prerequisites:
- Install the necessary build dependencies
- Bootstrap the AWS account
- Initialize the CDK application.
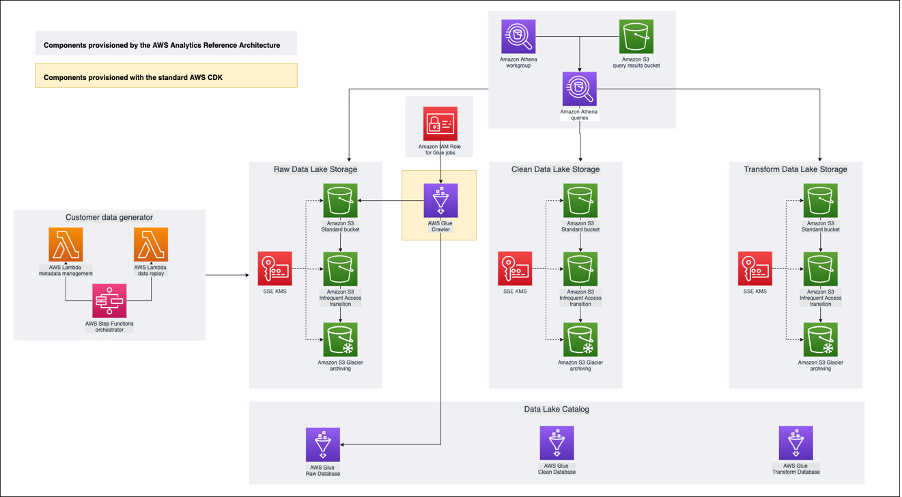
This architecture diagram depicts the data lake building blocks we are going to deploy using the AWS Analytics Reference Architecture library. These are higher level constructs (commonly called L3 constructs) as they integrate several AWS services together in patterns.

To assemble these components, you can add this code snippet in your app.py file:
import aws_analytics_reference_architecture as ara
... # Create a new DataLakeStorage with Raw, Clean and Transform buckets storage = ara.DataLakeStorage(scope=self, id="storage") # Create a new DataLakeCatalog with Raw, Clean and Transform databases catalog = ara.DataLakeCatalog(scope=self, id="catalog") # Configure a new Athena Workgroup athena_defaults = ara.AthenaDemoSetup(scope=self, id="demo_setup") # Generate data from Customer TPC dataset data_generator = ara.BatchReplayer( scope=self, id="customer-data", dataset=ara.PreparedDataset.RETAIL_1_GB_CUSTOMER, sink_object_key="customer", sink_bucket=storage.raw_bucket, ) # Role with default permissions for any Glue service glue_role = ara.GlueDemoRole.get_or_create(self) # Crawler to create tables automatically crawler = glue.CfnCrawler(self, id='ara-crawler', name='ara-crawler', role=glue_role.iam_role.role_arn, database_name='raw', targets={'s3Targets': [{"path": f"s3://{storage.raw_bucket.bucket_name}/{data_generator.sink_object_key}/"}],} ) # Trigger to kick off the crawler cfn_trigger = glue.CfnTrigger(self, id="MyCfnTrigger", actions=[{'crawlerName': crawler.name}], type="SCHEDULED", description="ara_crawler_trigger", name="min_based_trigger", schedule="cron(0/5 * * * ? *)", start_on_creation=True, )In addition to this library construct, the example also includes lower level constructs (commonly called L1 constructs) from the AWS CDK standard library. This shows that you can combine constructs from any CDK library interchangeably.
For use cases where customers have a need to adjust the default configurations in order to align with their organization specific requirements (e.g. data retention rules), the constructs can be changed through the class parameters as shown in this example:
storage = ara.DataLakeStorage(scope=self, id="storage", raw_archive_delay=180, clean_archive_delay=1095)
Finally, you can deploy the solution using the AWS CDK CLI from the root of the application with this command: cdk deploy. Once you deploy the solution, AWS CDK provisions the AWS resources included in the Constructs and you can log into your AWS account.
Go to the Athena console and start querying the data. The AthenaDemoSetup provides an Athena workgroup called “demo” that you can select to start querying the BatchReplayer data very quickly. Data is stored in the DataLakeStorage and registered in the DataLakeCatalog. Here is an example of an Athena query accessing the customer data from the BatchReplayer:

Accelerate the implementation
Earlier in the post we pointed out that the library simplifies and accelerates the development process. First, writing Python code is more appealing than writing CloudFormation markup code, either in json or yaml. Second, the CloudFormation template generated by the AWS CDK for the data lake example is 16 times more verbose than Python scripts.
❯ cdk synth | wc -w
2483
❯ wc -w ara_demo/ara_demo_stack.py
154
Demonstrating end-to-end examples with reference architectures
The AWS native reference architecture is the first reference architecture available. It explains the journey of a fake company, MyStore Inc., as it implements its data platform solution with AWS products and services . Deploying the AWS native reference architecture demonstrates a fully working example of a data platform from data ingestion to business analysis. AWS customers can learn from it, see analytics solutions in action, and play with retail dataset and business analysis.
More reference architectures will will be added to this project in Github later.
Business Story
The AWS native reference architecture is faking a retail company called MyStore Inc. that is building a new analytics platform on top of AWS products. This example shows how retail data can be ingested, processed, and analyzed in streaming and batch processes to provide business insights like sales analysis. The platform is built on top of the CDK Constructs from the core library to minimize development effort and inherit from AWS best practices.
Here is the architecture deployed by the AWS native reference architecture:

The platform is implemented in purpose-built modules. They are decoupled and can be independently provisioned but still integrate with each other. The global platformMyStore’s analytics platform has been able to deploy the following modules thanks to:
- Data Lake foundations: This mandatory module (based on DataLakeCatalog and DataLakeStorage core constructs) is the core of the analytics platform. It contains the data lake storage and associated metadata for both batch and streaming data. The data lake is organized in multiple Amazon S3 buckets representing different versions of the data. (a) The raw layer contains the data coming from the data sources in the raw format. (b) The cleaned layer contains the raw data that has been cleaned and parsed to a consumable schema. (c) And the curated layer contains refactored data based on business requirements.
- Batch analytics: This module is in charge of ingesting and processing data from a Stores channel generated by the legacy systems in batch mode. Data is then exposed to other modules for downstream consumption. The data preparation process leverages various features of AWS Glue, a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development via the Apache Spark framework. The orchestration of the preparation is handled using AWS Glue Workflows that allows managing and monitoring executions of Extract, Transform, and Load (ETL) activities involving multiple crawlers, jobs, and triggers. The metadata management is implemented via AWS Glue Crawlers, a serverless process that crawls data sources and sinks to extract the metadata including schemas, statistics and partitions. It saves them in the AWS Glue Data Catalog.
- Streaming analytics: This module is ingesting and processing real time data from the Web channel generated by cloud native systems. The solution minimizes data analysis latency but also to feed the data lake for downstream consumption.
- Data Warehouse: This module is ingesting data from the data lake to support reporting, dashboarding and ad hoc querying capabilities. The module is using an Extract, Load, and Transform (ELT) process to transform the data from the Data Lake foundations module. Here are the steps that outline the data pipeline from the data lake into the data warehouse. 1. AWS Glue Workflow reads CSV files from the Raw layer of the data lake and writes them to the Clean layer as Parquet files. 2. Stored procedures in Amazon Redshift’s stg_mystore schema extract data from the Clean layer of the data lake using Amazon Redshift Spectrum. 3. The stored procedures then transform and load the data into a star schema model.
- Data Visualization: This module is providing dashboarding capabilities to business users like data analysts on top of the Data Warehouse module, but also provides data exploration on top of the Data Lake module. It is implemented with Amazon Quicksight, a scalable, serverless, embeddable, and machine learning-powered business intelligence tool. Amazon QuickSight is connected to the data lake via Amazon Athena and the data lake via Amazon Redshift using direct query mode, in opposition to the caching mode with SPICE.
Project Materials
The AWS native reference architecture provides both code and documentation about MyStore’s analytics platform:
- Documentation is available on GitHub and comes in two different parts:
- The high level design describes the overall data platform implemented by MyStore, and the different components involved. This is the recommended entry point to discover the solution.
- The analytics solutions provide fine-grained solutions to the challenges MyStore met during the project. These technical patterns can help you choose the right solution for common challenges in analytics.
- The code is publicly available here and can be reused as an example for other analytics platform implementations. The code can be deployed in an AWS account by following the getting started guide.
Conclusion
In this blog post, we introduced new AWS CDK content available for customers and partners to easily implement AWS analytics solutions with the AWS Analytics Reference Architecture. The core library provides reusable building blocks with best practices to accelerate the development life cycle on AWS and the reference architecture demonstrates running examples with end-to-end integration in a business context.
Because of its reusable nature, this project will be the foundation for lots of additional content. We plan to extend the technical scope of it with Constructs and reference architectures for a data mesh. We’ll also expand the business scope with industry focused examples. In a future blog post, we will go deeper into the constructs related to Amazon EMR Studio and Amazon EMR on EKS to demonstrate how customers can easily bootstrap an efficient data platform based on Amazon EMR Spark and notebooks.
