Amazon’s Exabyte-Scale Migration from Apache Spark to Ray on Amazon EC2
July 25, 2024Large-scale, distributed compute framework migrations are not for the faint of heart. There are backwards-compatibility constraints to maintain, performance expectations to meet, scalability limits to overcome, and the omnipresent risk of introducing breaking changes to production. This all becomes especially troubling if you happen to be migrating away from something that successfully processes exabytes of data daily, delivers critical business insights, has tens of thousands of customers that depend on it, and is expected to have near-zero downtime.
But that’s exactly what the Business Data Technologies (BDT) team is doing at Amazon Retail right now. They just flipped the switch to start quietly moving management of some of their largest production business intelligence (BI) datasets from Apache Spark over to Ray to help reduce both data processing time and cost. They’ve also contributed a critical component of their work (The Flash Compactor) back to Ray’s open source DeltaCAT project. This contribution is a critical first step toward letting other users realize similar benefits when using Ray on Amazon Elastic Compute Cloud (Amazon EC2) to manage open data catalogs like Apache Iceberg, Apache Hudi, and Delta Lake.
So, what convinced them to take this risk? Furthermore, what inspired them to choose Ray – an open source framework known more for machine learning (ML) than big data processing – as the successor to Spark for this workload? To better understand the path that led them here, let’s go back to 2016.
Background
In 2016, Amazon was on a company-wide mission to remove all of its dependencies on Oracle, and that also meant completing a major migration of its BI infrastructure. They were, at the time, running what some surmised to be the largest Oracle Data Warehouse on Earth. But, with over 50 petabytes of data in tow, the Oracle Data Warehouse was pushing its scalability limits, falling short of performance expectations, and stretching the bounds of any practical BI budget. Amazon’s proposed answer to this is now a familiar best practice – to decouple storage and compute so they can scale independently of each other. For storage, BDT chose Amazon Simple Storage Service (Amazon S3) and, for compute, they started with a mix of Amazon Redshift, Amazon Relational Database Service (Amazon RDS), and Apache Hive on Amazon EMR. After a few false starts, they successfully copied over 50PB of Oracle table data to S3, converting it to universally-consumable content types like delimited text and wrapping each table in a more generic schema based on the Amazon Ion type system enroute.
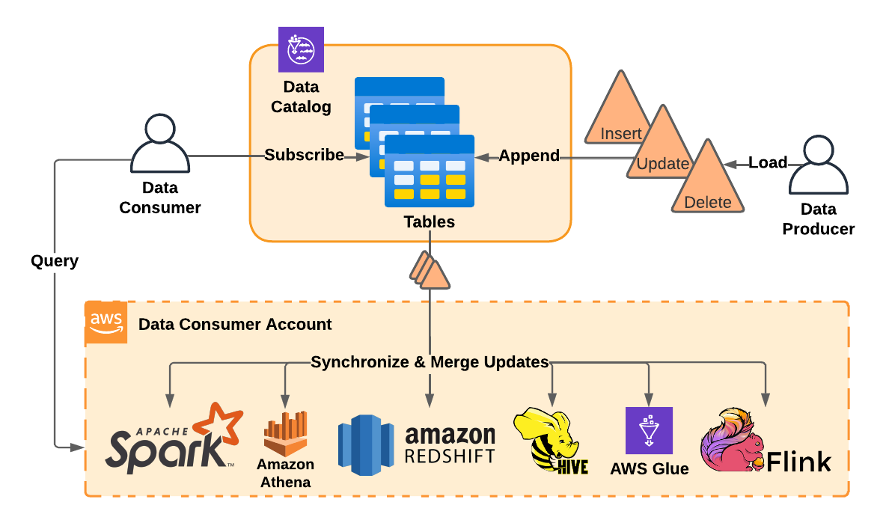
Next, they built a table subscription service that allowed anyone at Amazon to “subscribe” to an S3-based table using their choice of data analytics framework (e.g. Amazon Athena, Apache Flink, Amazon Redshift, Apache Hive, AWS Glue, Apache Spark, etc.). Once subscribed, their customers could use this compute framework to either query a table’s contents on demand or automatically trigger queries whenever new data arrived. BDT then built data cataloging metadata layers over Amazon S3, data discovery services, job orchestration infrastructure, web service APIs and UIs, and finally released the minimum viable set of services they needed to replace Oracle. They shut down their last Oracle Data Warehouse cluster in 2018 and declared the migration to be complete.

Figure 1: BDT’s table subscription service lets data consumers subscribe to data catalog tables and run on-demand or scheduled queries using a compute framework of their choice. The compute framework or service running the query merges in the latest inserts, updates, and deletes from data producers before returning results.
However, it wasn’t long before they were facing another serious scaling problem with their table subscriptions. This problem was due to all tables in their catalog being composed of unbounded streams of Amazon S3 files, where each file contained records to either insert, update, or delete. It was the responsibility of each subscriber’s chosen compute framework to dynamically apply, or “merge,” all of these changes at read time to yield the correct current table state. Unfortunately, these change-data-capture (CDC) logs of records to insert, update, and delete had grown too large to merge in their entirety at read time on their largest clusters. Tables were also increasingly displaying unwieldy problems like millions of kilobyte-scale tiny files or a few terabyte-scale huge files to merge. New subscriptions to their largest tables would take days or weeks to complete a merge, or they would just fail.
To solve this problem, BDT leveraged Apache Spark on Amazon EMR to run the merge once and then write back a read-optimized version of the table for other subscribers to use (a process now referred to as a “copy-on-write” merge by open-source projects like Apache Iceberg and Apache Hudi). By basing their data consumer’s reads on this pre-merged table they were able to minimize the number of records merged at read time. BDT called this Apache Spark job the “compactor,” since it would reduce (or “compact”) a CDC log stream consisting of N insert, update, and delete deltas across M files down to a single “insert” delta containing the final set of records to read split across K equivalently sized files.

Figure 2: Append-only compaction. Append deltas arrive in a table’s CDC log stream, where each delta contains pointers to one or more S3 files containing records to insert into the table. During a compaction job, no records are updated or deleted so the delta merge is a simple concatenation, but the compactor is still responsible for writing out files sized appropriately to optimize reads (i.e. merge tiny files into larger files and split massive files into smaller files).

Figure 3: Upsert compaction. Append and Upsert deltas arrive in a table’s CDC log stream, where each Upsert delta contains records to update or insert according to one or more merge keys. In this case, column1 is used as the merge key, so only the latest column2 updates are kept per distinct column1 value.
The Problem with the Spark Compactor
By 2019, Amazon’s petabyte-scale data catalog had grown to exabyte-scale, and their Apache Spark compactor was also starting to show some signs of its age. Compacting all in-scope tables in their catalog was becoming too expensive. Manual job tuning was required to successfully compact their largest tables, compaction jobs were exceeding their expected completion times, and they had limited options to resolve performance issues due to Apache Spark successfully (and unfortunately in this case) abstracting away most of the low-level data processing details.
BDT continued to improve their Apache Spark compactor, and also evaluated several options to improve compaction outside of Apache Spark, including running it on an in-house distributed compute service that they were already using for table management operations like schema/partition evolution and data repair. Although this service had the right fundamental primitives of distributed stateless functions (tasks) and distributed stateful classes (actors) needed to produce a more optimal implementation of compaction, they were reluctant to use it due to maintainability concerns stemming from a complex programming model and efficiency concerns from high task invocation overhead and no cluster autoscaling support.
Then BDT came across an interesting paper about Ray and met with the team working on it at UC Berkeley RISELab to learn more. They came away with an understanding of how Ray could be used by their data and ML scientists to more simply scale their applications, but they also believed that Ray could provide a better solution to their compaction problem. Ray’s intuitive API for tasks and actors, horizontally-scalable distributed object store, support for zero-copy intranode object sharing, efficient locality-aware scheduler, and autoscaling clusters offered to solve many of the key limitations they were facing with both Apache Spark and their in-house table management framework.
The Spark-to-Ray Migration
In 2020, BDT completed an initial proof-of-concept (PoC) of compaction on Ray and found during manual testing on production datasets that, with proper tuning, it could compact 12X larger datasets than Apache Spark, improve cost efficiency by 91%, and process 13X more data per hour. There were many factors that contributed to these results, including Ray’s ability to reduce task orchestration and garbage collection overhead, leverage zero-copy intranode object exchange during locality-aware shuffles, and better utilize cluster resources through fine-grained autoscaling. However, the most important factor was the flexibility of Ray’s programming model, which let them hand-craft a distributed application specifically optimized to run compaction as efficiently as possible. For example, BDT was able to add low-level optimizations like copying untouched Amazon S3 files by reference during a distributed merge on Ray instead of rewriting them. BDT didn’t need a generalist for the compaction problem, but a specialist, and Ray let them narrow their focus down to optimizing the specific problem at hand.
By 2021, they had settled on an initial distributed system design for serverless job management using Ray on EC2 together with Amazon DynamoDB, Amazon Simple Notification Service (Amazon SNS), Amazon Simple Queue Service (Amazon SQS), and Amazon S3 for durable job lifecycle tracking and management. They presented a high-level overview of this design together with their initial Ray Compaction PoC results back at the 2021 Ray Summit, and contributed an initial implementation of their Ray compactor back to the Ray DeltaCAT project with the goal of extending it to run on other open catalogs like Apache Iceberg, Apache Hudi, and Delta Lake. Today, the emergence of services like the Anyscale Platform and AWS Glue for Ray mean that Ray users no longer need to build their own serverless Ray job management system from scratch.

Figure 4: BDT’s initial high-level design for running compaction jobs with Ray on Amazon EC2. Some details of this design have changed over time, but the same high-level components continue to be used in production. The solid lines of the primary workflow show the required steps needed to start and complete compaction jobs, while the dashed lines in the secondary workflow show the steps supporting job observability. Dedicated service teams focus on problems outside the scope of this diagram like load prediction and pre-emptive Ray cluster Amazon EC2 instance provisioning.
In 2022, BDT put serverless job management and data processing on Ray to an early test by integrating it into a new service that delivered data quality insights for all tables in their production data catalog. This service used Ray to efficiently compute dataset statistics, inspect trends, and proactively find anomalies hiding in exabytes of production data. This was also their first opportunity to work out any issues uncovered by throwing Ray at exabyte-scale production data volumes before placing it on any business-critical data processing path. The chief problems they encountered revolved around the management of Amazon EC2 instances at scale (e.g. poor Amazon EC2 resource utilization and slow cluster start times) and out-of-memory errors.
BDT resolved most out-of-memory errors by telegraphing expected memory usage at Ray task invocation time (via memory-aware-scheduling) based on past trends. They were likewise able to resolve most of their Amazon EC2 infrastructure management issues by observing historic Amazon EC2 resource utilization trends, then using this information to preemptively provision heterogeneous clusters composed of different Amazon EC2 instance types spanning multiple availability zones. Ideally, all Amazon EC2 instances required by a job are provisioned and ready to use right before they’re actually needed. Their approach involves first finding a set of potential Amazon EC2 instance types that can meet expected hardware resource requirements, then provisioning the most readily available instance types from that set. As a side effect, they effectively trade knowing exactly what Amazon EC2 instance type a Ray cluster will get for provisioning pseudo-random instance types faster. This also means that BDT’s Ray applications need to remove any assumptions about their underlying CPU architectures, disk types, or other hardware. Amazon EC2 infrastructure management is a large challenge by itself, so multiple internal service teams at Amazon continue to own and improve separate parts of this solution.

Figure 5: BDT creates heterogenous Ray clusters by first discovering a set of EC2 instance types that can meet expected resource requirements, then provisioning the most readily available instance types from that set. For example, if their resource manager expects an upcoming job needs 1TiB of RAM and 128 vCPUs then it might provision one R6G-16xlarge instance with 64 vCPUs and 512GiB of RAM from availability zone 1, then provision the remaining 64 vCPUs and 512GiB of RAM using the most readily available mix of R6G-8xlarge and R5-4xlarge instances from availability zone 2.
By late 2022, BDT had built enough confidence in Ray, their proof-of-concept compactor, and their serverless job management infrastructure to start the migration from Apache Spark to Ray in earnest. As a first step, they created a priority-ordered list of tables to migrate to Ray-based compaction so that they could focus on migrating the tables that would yield the biggest impact first. They wound up targeting the largest ~1% of tables in their catalog, since they found that these accounted for ~40% of their overall Apache Spark compaction cost and the vast majority of their compaction job failures. BDT then started manually shadowing a subset of Apache Spark compaction jobs on Ray by giving it the same input dataset as Apache Spark. They then relied on their Ray-based data quality service to compare their respective outputs for equivalence.
During data quality (DQ) analysis, BDT primarily focused on equality of high-level dataset statistics like record counts, cardinalities, and min/max/avg values. They also compared file-level attributes like Apache Parquet file format versions, and whether they were using the same Apache Parquet file features (e.g. if Apache Spark didn’t produce an Apache Parquet file with an embedded Bloom Filter, then they made sure that Ray didn’t either). Anything that didn’t pass DQ would be the target of a manual analysis, and either become a known/accepted difference to document or an issue to fix. Lastly, they built a Data Reconciliation Service which compared the results of actually subscribing to and querying both Apache Spark and Ray-produced tables across multiple compute frameworks like Amazon Redshift, Apache Spark, and Amazon Athena.
NOTE: It may also be worth noting that BDT intentionally did not compare table outputs for absolute byte-for-byte equality, because queries run on different compute frameworks against GB/TB/PB-scale datasets almost never produce equal results at this granularity. This is often due to things like decimal rounding differences, non-deterministic execution plans (e.g. using an unstable sort somewhere), adding/removing metadata from Parquet files, different limits and handling for value overflows/underflows, different type comparison opinions like whether -0 equals 0 (assuming both type systems even have a concept of -0!) or whether two timestamps should be considered equal regardless of timezone (again, assuming both type systems even persist timezone information!), pre-Gregorian calendar date interpretation differences, accurately accounting for edge-cases like leap seconds in timestamps, etc.
In 2023, once BDT felt like they had most of their known issues/discrepancies documented and required fixes deployed, they moved onto fully automated shadow compaction on Ray. This step required automatic 1:1 shadowing of all compaction jobs for any given table between Apache Spark and Ray. So, whenever new inserts/updates/deletes arrived in a table to be compacted, both Apache Spark and Ray would kick off the same compaction job. The purpose of this step was to get more direct comparisons with Apache Spark, verify that Ray’s benefits held up across a wide variety of notoriously problematic tables, and to smoke out any latent corner-case issues that only appeared at scale. This step also meant that they would temporarily, but significantly, increase their overall cost of compaction before lowering it. If everything crashed and burned at this point, it would become a capital loss for the business and filed away as a hard lesson learned.

Figure 6: The Apache Spark/Ray shadow compaction, data quality, and data reconciliation workflow that BDT uses to reduce risk before transitioning table subscribers over to consuming Ray-compacted datasets. New deltas arriving in a data catalog table’s CDC log stream are merged into two separate compacted tables maintained separately by Apache Spark and Ray. The Data Reconciliation Service verifies that different data processing frameworks produce equivalent results when querying datasets produced by Apache Spark and Ray, while the Ray-based DQ Service compares key dataset statistics.
To help avoid catastrophic failure, BDT built another service that let them dynamically switch individual table subscribers over from consuming the Apache Spark compactor’s output to Ray’s output. So, instead of just having Ray overwrite the Apache Spark compactor’s output in-place and hoping all goes well for thousands of table subscribers, they can move subscribers over from consuming Apache Spark’s output to Ray’s output one at a time while maintaining the freedom to reverse course at the first sign of trouble.
Results
During the first quarter of 2024, BDT used Ray to compact over 1.5EiB of input Apache Parquet data from Amazon S3, which translates to merging and slicing up over 4EiB of corresponding in-memory Apache Arrow data. Processing this volume of data required over 10,000 years of Amazon EC2 vCPU computing time on Ray clusters containing up to 26,846 vCPUs and 210TiB of RAM each.
BDT continues to read over 20PiB/day of input S3 data to compact across more than 1600 Ray jobs/day. The average Ray compaction job now reads over 10TiB of input Amazon S3 data, merges new table updates, and writes the result back to Amazon S3 in under 7 minutes including cluster setup and teardown. From the last quarter of 2023 through the first quarter of 2024, Ray has maintained a 100% on-time delivery rate of newly compacted data to table subscribers. This means that over 90% of all new table updates are applied by Ray and available to query within 60 minutes of arrival.
What’s more impressive, is that Ray has been able to do all this with 82% better cost efficiency than Apache Spark per GiB of S3 input data compacted. For BDT, this efficiency gain translates to an annual saving of over 220,000 years of EC2 vCPU computing time. From the typical Amazon EC2 customer’s perspective, this translates to saving over $120MM/year on Amazon EC2 on-demand R5 instance charges.

Figure 7: Efficiency comparison between Ray and Spark measuring the minutes each took to compact 1GiB of the same production Apache Parquet data in Amazon S3 using equivalent memory-optimized Amazon EC2 instance types across more than 1.2EiB of Amazon S3 input data.
While these results look very promising, there’s still plenty of room for improvement. BDT is only using Ray to apply updates to a minority of their data catalog tables today, and would like to see a longer track record of consistent reliability before onboarding more tables to Ray compaction. For example, Ray’s first-time compaction job success rate trailed Spark by up to 15% in 2023 and by nearly 1% in 2024. This translates to Ray needing more compaction job retries than Apache Spark to successfully apply new table updates on average, and to Ray requiring more manual overhead to operate at scale.

Figure 8: Reliability comparison between Ray and Apache Spark measuring the average success rate of all compaction jobs across the trailing four weeks (inclusive) of the given weekly reporting period. Both Apache Spark and Ray used equivalent memory-optimized Amazon EC2 instance types to compact equivalent data across more than 215K job runs.
While Ray is closing the reliability gap between it and Apache Spark in 2024 with an average initial job success rate of 99.15%, this is still 0.76% behind Apache Spark’s average initial job success rate of 99.91%. Cluster sizing has also been difficult to dial in to maximize both efficiency and stability. This can be better understood by taking a look at BDT’s Ray compaction cluster memory utilization. During the first quarter of 2024, BDT consistently used about 19.4TiB of 36TiB of total cluster memory allocated for all in-progress Ray compaction jobs. This brought their average memory utilization efficiency to 54.6% and, since memory is their bottleneck, the average utilization rate of other resources like CPU, network bandwidth, and disk space was even lower. This gap between available vs. used Amazon EC2 resources meant that the Ray compactor’s actual cost efficiency gain versus Apache Spark was lower than its potential. For example, if BDT improved their Ray compactor to use 90% of available cluster memory on average, then its corresponding cost efficiency improvement vs. Apache Spark would also improve from 82% to over 90%.

What’s Next?
Finally, as BDT continues actively working on a new major revision of The Flash Compactor that takes better advantage of Ray features like pipelining and autoscaling, they’re starting to again see a clear line of sight back to the scale of efficiency improvements observed in their initial hand-tuned PoC of petabyte-scale compaction on Ray presented at the 2021 Ray Summit. By the end of 2024 they hope to see their average efficiency improvement increase to over 90% vs. Spark across all production tables with no manual parameter tuning or human intervention required.
Part of what’s driving ongoing improvements is a joint effort to improve data processing on Ray between Amazon and the Daft Project. For example, a recent improvement to S3 Parquet and delimited text file I/O efficiency on Ray with Daft resulted in an impressive 24% production compaction cost efficiency improvement vs. compaction on Ray without Daft.

Figure 10: Benchmark figures for improved Amazon S3 Apache Parquet file reads using Daft vs. PyArrow and DeltaCAT on S3Fs. Note that the median read time for a single column improved by 55% vs. PyArrow and 91% vs. S3Fs, while the median read time for a full file improved by 19% vs. Pyarrow and 77% vs. S3Fs. Deploying these performance improvements to production resulted in an additional 24% cost efficiency improvement for BDT’s Ray compactor.
So, do these results imply that you should also start migrating all of your data processing jobs from Apache Spark to Ray? Well, probably not – not yet, at least. Data processing frameworks like Apache Spark continue to offer feature-rich abstractions for data processing that will likely continue to work well enough for day-to-day use-cases. There’s also no paved road today to automatically translate your Apache Spark applications over to Ray-native equivalents that run with similar or better efficiency on Ray.
However, Amazon’s results with compaction specifically, and studies like Exoshuffle generally (which holds the 2022 Cloud Terasort benchmark cost record) indicate that Ray has the potential to be both a world-class data processing framework and a world-class framework for distributed ML. And if you, like BDT, find that you have any critical data processing jobs that are onerously expensive and the source of significant operational pain, then you may want to seriously consider converting them over to purpose-built equivalents on Ray.
