Announcing the AWS CDK Glue L2 Construct
January 30, 2025Today, we’re announcing the release of the new AWS Cloud Development Kit (CDK) L2 construct for AWS Glue. This construct simplifies the correct configuration of Glue jobs, workflows, and triggers. Reviewing Glue documentation and examples of the valid parameters for each job type and language takes time, and having to rely on synth, deploy, and run-time error handling to verify configuration choices can be a frustrating developer experience. With this new construct, developers can leverage constructors that are specific to job type. The new constructors default to opinionated best-practice configuration and leverage convenience functions that reduce the time to build repeatable ETL solutions. The new Glue CDK L2 construct is available in alpha stage and will be rolled into the core CDK library after stabilization.
Background
The AWS CDK is an open-source software development framework to define cloud infrastructure in code using modern programming languages and provision it through AWS CloudFormation. It uses layering through Constructs to provide different levels of abstraction for using cloud components. Layering ensures that you never have to write too much code or have too little access to resource properties when you deploy your infrastructure as code (IaC) stacks. Layer 1 (L1) constructs map directly to CloudFormation primitives, while Layer 2 (L2) constructs provide helper functions and best practice defaults that improve the developer experience and make it easier to do the right thing.
Defining Glue resources at scale presents several challenges that this L2 construct resolves. First, developers must reference documentation to determine the valid combinations of job type, Glue version, worker type, language versions, and other parameters that are only valid in finite combinations. Additionally, developers must already know or look up the networking constraints for data source connections, and there is ambiguity with how to securely store secrets for JDBC connections. Finally, developers want prescriptive guidance via best practice defaults for throughput parameters like number of workers and batching.
The new Glue L2 construct has convenience methods and constructors that work backwards from common use cases and sets required parameters to defaults that align with recommended best practices for each job type. It also provides customers with a balance between flexibility via optional parameter overrides, and opinionated interfaces that discourages anti-patterns, resulting in reduced time to develop and deploy new resources.
Using the L2
The L2 construct only exposes the parameters that apply to each job and workflow type through their respective constructors. For instance, Python and Ray jobs don’t need to configure the Scala job parameters of extra jar files or a main class from which to start execution. Using the construct, the language and job specific configuration elements are in their own interface definitions for properties, keeping the configuration elements that are common across all jobs like job name, job description, and CloudWatch metrics in the parent job class. It also aligns to the same best practice defaults that the Glue Studio console experience provides, which provides a consistent experience when using console and CDK.

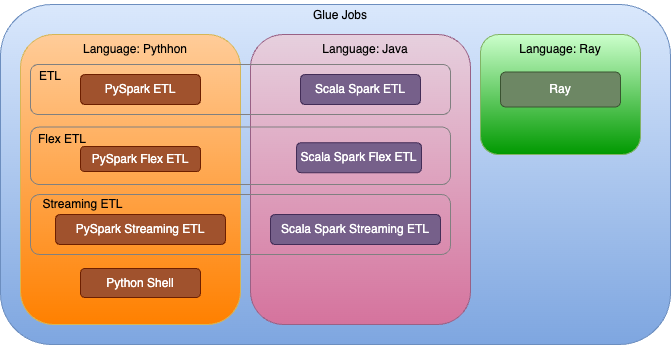
Figure 1 – Hierarchy of Glue job type and language support showing the configuration options
The new construct automatically sets the Glue job type that maps to the constructor the developer used to create the job, and sets the Glue version and language version to the latest supported version for the service. In addition, it sets defaults for parameters that the developer would otherwise have to experiment with such as timeout, number of workers, and max retries.
These interfaces, inheritance, and default values allow to us to create constructors that only require a few parameters to create a complete job, as opposed to the nearly 2 dozen options and even more numerous permutations of the valid and invalid combinations that could be made experimenting with the L1 construct. Enforcing values via interfaces means that the developer gets fail-fast feedback on the correct allowed configuration before synth or deploy time via autocomplete and Q Developer code recommendations as well.
While the construct is in the alpha stage, you’ll need to follow the process for using experimental construct libraries. After stabilization, the library will be rolled into the core CDK library and you can use it just like any other L1 or L2 construct.
Creating a new Python Spark ETL Glue Job in Typescript
The following example shows how to create a new Python Spark ETL Glue Job in Typescript.
glue_job = new glue.PySparkEtlJob(stack, 'PySparkETLJob', { glueIamRole, glue.Code.fromAsset('glue-jobs/helloworld.py'), jobName: 'PySparkETLJob',
});If a developer were to override all of the optional values, the most verbose provisioning option would look like this:
glue_job = new glue.PySparkEtlJob(stack, 'PySparkETLJob', { jobName: 'PySparkETLJobCustomName', description: 'This is PySpark ETL Job', glueIamRole, glue.Code.fromAsset('glue-jobs/helloworld.py'), glueVersion: glue.GlueVersion.V3_0, continuousLogging: { enabled: false }, workerType: glue.WorkerType.G_2X, maxConcurrentRuns: 100, timeout: cdk.Duration.hours(2), connections: [glue.Connection.fromConnectionName(stack, 'Connection', 'connectionName')], securityConfiguration: glue.SecurityConfiguration.fromSecurityConfigurationName(stack, 'SecurityConfig', 'securityConfigName'), tags: { FirstTagKey: 'FirstTagValue', SecondTagKey: 'SecondTagValue', XTagKey: 'XTagValue', }, numberOfWorkers: 2, maxRetries: 2, });
Creating On-Demand Workflow Triggers
The new construct also simplifies the way workflows and triggers are provisioned, leveraging the existing Schedule class to define the correct frequency of execution. It also provides helper functions to add different types of triggers.
The following example shows how to create a On-Demand Workflow Trigger.
myWorkflow = new glue.Workflow(this, "GlueWorkflow", { name: "MyOnDemandWorkflow"; description: "New On Demand Workflow";
}); myWorkflow.addOnDemandTrigger(this, 'TriggerJobOnDemand', { actions: [{ glue_job }]
});For more examples of how to create other job types and trigger configurations, review the Glue L2 construct documentation.
Considerations when moving to the new construct
The new construct maintained its existing functionality for Connections and Databases, Tables, and Job Run Queueing, since they’re consistent for all job types. It also enables CloudWatch logging and (if applicable) SparkUI logging by default, so using this construct will leverage those best-practice observability features unless you explicitly turn them off.
If you’re currently using an older version of Glue or of the language your Glue job supports, we recommend that you consider using this construct launch as part of an upgrade plan to take advantage of the performance, functionality, and language security enhancements for newer versions. If you prefer to stay on older versions of the service or language, we recommend you migrate to the L1 construct which isn’t opinionated about enforcing the latest versions by default.
Conclusion
The AWS CDK Glue L2 construct will migrate from its current alpha state to the AWS CDK core library after it completes the stabilization phase, which usually takes 3 months. For more details on the new Glue L2 construct and examples of its use, see the Glue CDK documentation. As always, if you have any feedback on the new construct or the CDK in general, you may create a GitHub issue on AWS CDK GitHub repository.
If you’re new to AWS CDK and want to get started, we highly recommend checking out the CDK documentation and the CDK workshop.
