Converting embedded SQL in Java applications with Amazon Q Developer
April 12, 2025As organizations modernize their database infrastructure, migrating from systems like Oracle to open source solutions such as PostgreSQL is becoming increasingly common. However, this transition presents a significant challenge: discovering and converting embedded SQL within existing Java applications to ensure compatibility with the new database system. Manual conversion of this code is time-consuming, error-prone, and can lead to extended downtime during migration. The process involves cautiously updating numerous SQL statements interwoven in Java code, which can take weeks depending on the application’s size and complexity. This manual approach is highly susceptible to errors, potentially introducing subtle bugs that are difficult to detect. It also requires deep expertise in both source and target database systems. Furthermore, ensuring consistency across the entire codebase during manual conversion is challenging. This can lead to inconsistencies in coding style, performance optimizations, and error handling. These factors combined make the SQL conversion process a significant bottleneck in database migration projects, often delaying modernization efforts and impacting business agility.
Solution
To address these challenges, AWS has introduced an innovative new capability: SQL code conversion using Amazon Q Developer in conjunction with AWS Database Migration Service (AWS DMS). This solution automates the process of transforming embedded SQL in Java applications, significantly reducing the time and effort required for database migrations.
Amazon Q Developer, a generative AI–powered assistant for software development that integrates directly into your Integrated Development Environment (IDE), offers a range of features to enhance developer productivity, including code generation, refactoring, and transformations such as java version upgrades and now SQL code conversion. It analyzes Java code, identifies embedded SQL statements, and automates conversion from the source dialect (e.g. Oracle) to the target dialect (e.g. PostgreSQL). This automation dramatically accelerates the conversion process, potentially reducing weeks of tedious work to just hours of effort.
The solution minimizes human error by leveraging AI algorithms trained on extensive SQL datasets, ensuring a level of consistency and accuracy difficult to achieve manually. It also allows developers to focus on higher-value tasks such as architecture optimization and performance tuning, rather than getting bogged down in the minutiae of SQL syntax differences. When combined with AWS Database Migration Service, which handles schema conversion and data replication, this solution creates a comprehensive migration workflow. It addresses not just code conversion but the entire database migration lifecycle, providing a streamlined path from legacy systems to modern database architectures. By automating SQL conversion, ensuring consistency across the codebase, and integrating with broader migration tools, this feature significantly simplifies the technical aspects of database migration. It aligns with organizational goals of improving efficiency, reducing costs, and maintaining competitiveness in an evolving technological landscape, making it a powerful tool for organizations undertaking database modernization projects.
Overview
To illustrate the power of this solution, let’s consider part of an application written in Java that manages shopping cart functionality for online retail operations using embedded Oracle SQL for database operations. The system allows customers to maintain their shopping carts, manage items, and handle basic e-commerce operations. In our sample application, we look at sections of code from a CartDAO.java class which has multiple Oracle-specific SQL queries. It demonstrates various Oracle-specific SQL features including regular expressions, XML handling, hierarchical queries, and analytical functions. These features make the code particularly optimized for Oracle databases. We’ll need to convert this SQL in order for it to be compatible PostgreSQL. Let’s explore each of these methods.
Method 1:
createItem is a basic insertion method that uses Oracle’s SYSDATE function to automatically timestamp the record. This is Oracle’s built-in function for current date and time.
public void createItem() throws SQLException { String sql = "INSERT INTO item (name, description, updated_date) VALUES (?, ?, SYSDATE)"; Connection conn = getConnection(); PreparedStatement pstmt = conn.prepareStatement(sql); pstmt.setString(1, "Sparkling Water"); pstmt.setDouble(2, 5.0); pstmt.executeUpdate(); System.out.println("Data inserted successfully");
}Method 2:
getMfgCodes is a method which uses Oracle’s SUBSTR function to retrieve the first three characters of an item name.
public List<String> getMfgCodes() throws SQLException { Connection conn = getConnection(); String sql = "SELECT DISTINCT(SUBSTR(name, 1, 3)) AS mfg_code FROM item"; Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery(sql); List<String> mfg_codes = new ArrayList<String>(); while (rs.next()) { mfg_codes.add(rs.getString("mfg_code")); } return mfg_codes;
}
Method 3:
findItemsByRegex leverages Oracle’s REGEXP_LIKE function, which provides pattern matching capabilities beyond standard SQL. This is used for complex string searching that would be difficult with simple LIKE clauses.
public List<String> findItemsByRegex(String pattern) throws SQLException { Connection conn = getConnection(); String sql = "SELECT name FROM item WHERE REGEXP_LIKE(name, ?)"; PreparedStatement pstmt = conn.prepareStatement(sql); pstmt.setString(1, pattern); ResultSet rs = pstmt.executeQuery(); List<String> names = new ArrayList<String>(); while (rs.next()) { names.add(rs.getString("name")); } return names;
}Method 4:
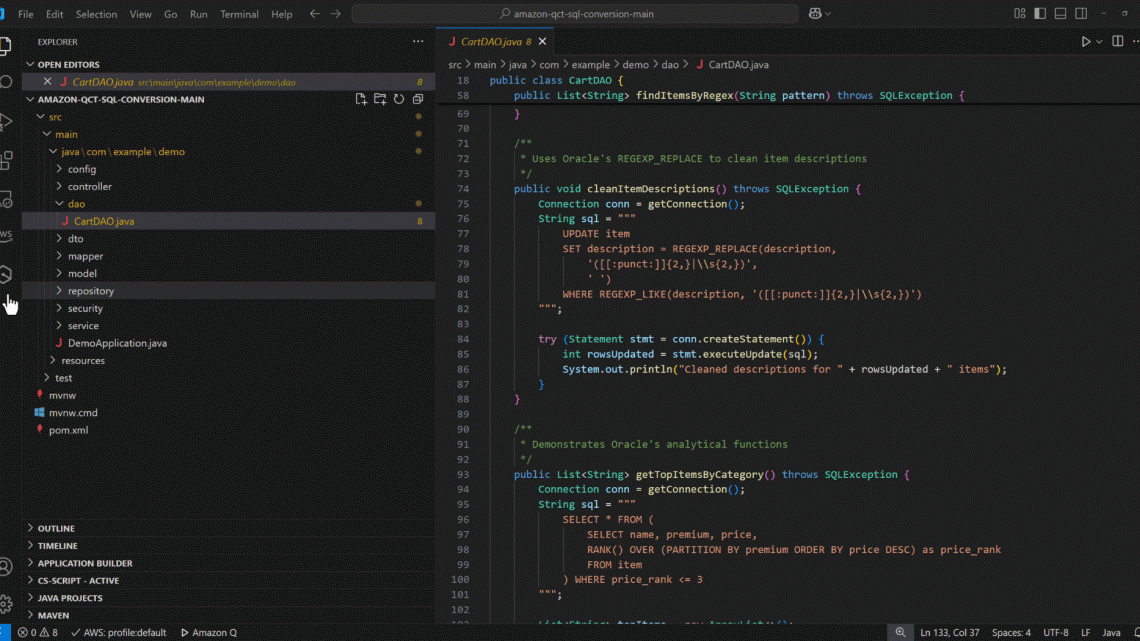
cleanItemDescriptions uses Oracle’s advanced regular expression capabilities through REGEXP_REPLACE. It specifically uses Oracle’s character class syntax [[:punct:]] to identify punctuation marks, which is an Oracle-specific implementation of POSIX regular expressions.
public void cleanItemDescriptions() throws SQLException { Connection conn = getConnection(); String sql = "UPDATE item SET description = REGEXP_REPLACE(description, " +" '([[:punct:]]{2,}|\\s{2,})', ' ') " +" WHERE REGEXP_LIKE(description, '([[:punct:]]{2,}|\\s{2,})') "; try (Statement stmt = conn.createStatement()) { int rowsUpdated = stmt.executeUpdate(sql); System.out.println("Cleaned descriptions for " + rowsUpdated + " items"); }
}Method 5:
This function retrieves the top 3 most expensive items for each premium category from the ‘item’ table using Oracle’s analytical RANK() function. It creates a formatted string for each item containing the premium category, item name, price, and its rank within its category. The results are stored in a List and returned.
public List<String> getTopItemsByCategory() throws SQLException { Connection conn = getConnection(); String sql = "SELECT * FROM (SELECT name, premium, price,RANK() OVER (PARTITION BY premium" +" ORDER BY price DESC) as price_rank FROM item) WHERE price_rank <= 3"; List<String> topItems = new ArrayList<>(); try (Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery(sql)) while (rs.next()) { String result = String.format("Premium: %s, Item: %s, Price: %.2f, Rank: %d", rs.getString("premium"), rs.getString("name"), rs.getDouble("price"), rs.getInt("price_rank")); topItems.add(result); } } return topItems;
}Method 6:
The SQL query in the findItemsByPriceRange method performs a targeted search and ranking operation on the item table in the database. It begins by filtering items to only those within a specific price bracket.
public List<String> findItemsByPriceRange() throws SQLException { Connection conn = getConnection(); String sql = "SELECT name, price, RANK() OVER (ORDER BY price) as price_rank FROM item" + "WHERE price BETWEEN ? AND ?"; List<String> items = new ArrayList<>(); try (PreparedStatement pstmt = conn.prepareStatement(sql)) { pstmt.setDouble(1, 50.0); pstmt.setDouble(2, 75.0); ResultSet rs = pstmt.executeQuery(); while (rs.next()) { String result = String.format("Item: %s, Price: %.2f, Rank: %d", rs.getString("name"), rs.getDouble("price"), rs.getInt("price_rank")); items.add(result); } } return items;
}Method 7:
This function demonstrates Oracle’s ROWNUM pseudo-column, which is a specific Oracle database feature used to limit the number of rows returned by a query. The function retrieves the first N items from the ‘item’ table by using ROWNUM <= ? in the WHERE clause.
public List<String> getFirstNItems(int n) throws SQLException { Connection conn = getConnection(); String sql = "SELECT name FROM item WHERE ROWNUM <= ?"; List<String> items = new ArrayList<>(); try (PreparedStatement pstmt = conn.prepareStatement(sql)) { pstmt.setInt(1, n); ResultSet rs = pstmt.executeQuery(); while (rs.next()) { items.add(rs.getString("name")); } } return items;
}Our goal is to convert these embedded Oracle specific queries to PostgreSQL queries.
Solution Walkthrough
Prerequisites
Before beginning the conversion process, ensure you have installed and configured Amazon Q in your IDE by following the setup guide. Your source codebase must be a Java application containing embedded Oracle SQL statements that you plan to migrate to PostgreSQL. The transformation specifically targets Oracle SQL syntax within Java code, so verify your application meets these requirements. Complete your database schema migration using AWS DMS Schema Conversion before starting the code transformation process. This crucial step creates the foundation for your PostgreSQL database structure.
Convert Embedded SQL
Open your Java application containing embedded SQL statements in your IDE where Amazon Q is installed. Access the Amazon Q chat panel by selecting the Amazon Q icon in your IDE interface. Start the transformation process by typing /transform in the chat panel. When prompted, specify ‘SQL conversion’ as your transformation type. Amazon Q validates your Java application’s eligibility for SQL conversion before proceeding.

Upload your schema metadata file when prompted by Amazon Q. The chat interface provides detailed instructions for retrieving this file from your previous DMS schema conversion process. Select your project containing embedded SQL and the corresponding database schema file from the dropdown menus in the chat panel. Amazon Q displays the detected database schema details for your confirmation. Take a moment to verify these details are accurate before proceeding with the conversion.

The SQL conversion process would begin, during which Amazon Q analyzes and transforms your Oracle SQL statements into PostgreSQL-compatible syntax.

For this application, Amazon Q was able to detect 7 Oracle specific queries in the code and was able to process them to the corresponding PostgreSQL queries. It generated a conversion summary of the embedded SQL statements processed, and shared recommended actions for 2 queries that needed further inspection.
Amazon Q presented a comprehensive diff view showing all proposed changes to the embedded SQL. Review each modification in the diff view carefully. After your review, accept the changes to update your codebase. Amazon Q generates a detailed transformation summary documenting all modifications made during the conversion.

Let’s take a look at how each of SQL statements within each function got converted to be compatible with PostgreSQL.
Method 1:
The key difference in this query involves the transition from Oracle’s SYSDATE function to PostgreSQL’s CLOCK_TIMESTAMP() with time zone handling. While SYSDATE in Oracle returns the current date and time of the database server, the PostgreSQL version uses CLOCK_TIMESTAMP() which provides the actual current time and explicitly handles timezone conversion through AT TIME ZONE.
public void createItem() throws SQLException { String sql = "INSERT INTO admin.item (name, description, updated_date) VALUES (?, ?, (CLOCK_TIMESTAMP() AT TIME ZONE COALESCE(CURRENT_SETTING('aws_oracle_ext.tz', TRUE), 'UTC'))::TIMESTAMP(0))"; Connection conn = getConnection(); PreparedStatement pstmt = conn.prepareStatement(sql); //pstmt.setInt(1, 1); pstmt.setString(1, "Sparkling Water"); pstmt.setDouble(2, 5.0); pstmt.executeUpdate(); System.out.println("Data inserted successfully");
}Method 2:
The key change in the next query involves using an extension pack added by the DMS Schema Conversion process which emulates source database functions. This is referenced using the fully qualified function name aws_oracle_ext.substr instead of the simple SUBSTR. The aws_oracle_ext schema contains Oracle-compatible functions to maintain compatibility with Oracle SQL syntax. Additionally, the table reference has been made more specific by including the schema name admin.item instead of just item, which helps avoid ambiguity in multi-schema environments.
public List<String> getMfgCodes() throws SQLException { Connection conn = getConnection(); String sql = "SELECT DISTINCT (aws_oracle_ext.substr(name, 1, 3)) AS mfg_code FROM admin.item"; Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery(sql); List<String> mfg_codes = new ArrayList<String>(); while (rs.next()) { mfg_codes.add(rs.getString("mfg_code")); } return mfg_codes;
}Method 3:
The next transformation demonstrates several important adaptations required for Oracle-compatible regular expression functionality in AWS. The key changes include: REGEXP_LIKE function has been replaced with its AWS Oracle extension equivalent aws_oracle_ext.regexp_like. Explicit type casting to TEXT has been added using the PostgreSQL-style cast operator:: TEXT for both the column name and the parameter. The schema qualifier admin has been added to the table name and extra parentheses have been added around the arguments for proper type handling. These modifications ensure that regular expression pattern matching works correctly in the AWS environment while maintaining Oracle-like functionality. The explicit TEXT type casting is particularly important as it ensures proper data type handling during the regular expression comparison operations.
public List<String> findItemsByRegex(String pattern) throws SQLException { Connection conn = getConnection(); String sql = "SELECT name FROM admin.item WHERE aws_oracle_ext.regexp_like((name)::TEXT, (?::TEXT)::TEXT)"; PreparedStatement pstmt = conn.prepareStatement(sql); pstmt.setString(1, pattern); ResultSet rs = pstmt.executeQuery(); List<String> names = new ArrayList<String>(); while (rs.next()) { names.add(rs.getString("name")); } return names;
}Method 4:
The next conversion shows several sophisticated adaptations required for Oracle-compatible regular expression functionality. The changes include the addition of the aws_oracle_ext schema prefix to both regexp_replace and regexp_like functions. The introduction of the E prefix before string literals containing escape sequences, which is PostgreSQL’s syntax for enabling escape sequence interpretation. Additional escaping of backslashes (from \s to \\s) has been added to properly handle whitespace matching in the AWS environment. Explicit type casting to TEXT using ::TEXT has been added for all arguments in both the regexp_replace and regexp_like functions. The schema qualifier admin has been added to the table name. Single quotes around the replacement space character have been wrapped with parentheses. These modifications ensure that the regular expression replacement and matching operations work correctly in the AWS environment while maintaining Oracle-like functionality. The pattern itself is designed to replace multiple consecutive punctuation marks or whitespace characters with a single space character.
public void cleanItemDescriptions() throws SQLException { Connection conn = getConnection(); String sql = "UPDATE admin.item SET description = aws_oracle_ext.regexp_replace((description)::TEXT, (E'([[:punct:]]{2,}|\\\\s{2,})')::TEXT, ('')::TEXT) WHERE aws_oracle_ext.regexp_like((description)::TEXT, (E'([[:punct:]]{2,}|\\\\s{2,})')::TEXT)"; try (Statement stmt = conn.createStatement()) { int rowsUpdated = stmt.executeUpdate(sql); System.out.println("Cleaned descriptions for " + rowsUpdated + " items"); }
}Method 5:
The next transformation shows a few key modifications required for proper execution in PostgreSQL. The addition of an explicit alias AS var_sbq for the derived subquery, which is required in PostgreSQL systems to properly reference derived tables The schema qualifier admin has also been added to the table name item.
public List<String> getTopItemsByCategory() throws SQLException { Connection conn = getConnection(); String sql = "SELECT * FROM (SELECT name, premium, price, RANK() OVER (PARTITION BY premium ORDER BY price DESC) AS price_rank FROM admin.item) AS var_sbq WHERE price_rank <= 3"; List<String> topItems = new ArrayList<>(); try (Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery(sql)) { while (rs.next()) { String result = String.format("Premium: %s, Item: %s, Price: %.2f, Rank: %d", rs.getString("premium"), rs.getString("name"), rs.getDouble("price"), rs.getInt("price_rank")); topItems.add(result); } } return topItems;
}Method 6:
The next transformation demonstrates a few important modifications for PostgreSQL compatibility: The addition of explicit type casting using ::NUMERIC for both parameters in the BETWEEN clause, which ensures proper numeric comparison and helps prevent type conversion issues The schema qualifier admin has been added to the table name item The window function RANK() syntax remains unchanged as it’s standard ANSI SQL.
public List<String> findItemsByPriceRange() throws SQLException { Connection conn = getConnection(); String sql = "SELECT name, price, RANK() OVER (ORDER BY price) AS price_rank FROM admin.item WHERE price BETWEEN ?::NUMERIC AND ?::NUMERIC"; List<String> items = new ArrayList<>(); try (PreparedStatement pstmt = conn.prepareStatement(sql)) { pstmt.setDouble(1, 50.0); pstmt.setDouble(2, 75.0); ResultSet rs = pstmt.executeQuery(); while (rs.next()) { String result = String.format("Item: %s, Price: %.2f, Rank: %d", rs.getString("name"), rs.getDouble("price"), rs.getInt("price_rank")); items.add(result); } } return items;
}Method 7:
The next transformation shows several significant changes for PostgreSQL compatibility. The Oracle-specific ROWNUM syntax has been replaced with the standard SQL LIMIT clause. A CASE expression has been added to handle input validation. TRUNC(?::NUMERIC) converts the input parameter to a numeric value and removes any decimal places. The CASE statement ensures that only positive numbers are accepted. If the input is less than or equal to 0, it returns 0 (effectively no rows). The schema qualifier admin has been added to the table name. The parameter is now used twice in the query (once for comparison and once for the actual limit). Type casting to NUMERIC has been added for safer numeric handling.
public List<String> getFirstNItems(int n) throws SQLException { Connection conn = getConnection(); String sql = "SELECT name FROM admin.item LIMIT CASE WHEN TRUNC(?::NUMERIC) > 0 THEN TRUNC(?::NUMERIC) ELSE 0 END"; List<String> items = new ArrayList<>(); try (PreparedStatement pstmt = conn.prepareStatement(sql)) { pstmt.setInt(1, n); ResultSet rs = pstmt.executeQuery(); while (rs.next()) { items.add(rs.getString("name")); } } return items;
}End-to-End Testing
After completing the SQL code conversion, update your application’s database connection settings to point to your new PostgreSQL database. This includes modifying connection strings, updating database credentials, and adjusting any database-specific configuration parameters.
Execute your application’s comprehensive test suite to validate the converted SQL statements. The test suite should cover all database interactions, ensuring queries return expected results and maintain proper data integrity. Pay particular attention to complex queries, stored procedure calls, and transaction management scenarios. Conduct thorough testing of your application’s critical paths. Focus on core business workflows that heavily depend on database operations. Test edge cases and error conditions to verify proper exception handling with the new PostgreSQL database. As a best practice recommendation, implement detailed monitoring of your application logs during testing. Watch for any SQL-related errors, unexpected query behavior, or performance degradation.
Conclusion
The combination of Amazon Q Developer and AWS DMS represents a significant leap forward in database migration technology. By automating the conversion of embedded SQL, we’ve addressed one of the most time-consuming and error-prone aspects of moving from Oracle to PostgreSQL.
Key benefits of this approach include:
- Reduced migration time: What once took weeks can now be accomplished in days or hours
- Improved accuracy: AI-powered conversion minimizes human error
- Cost savings: Less developer time spent on manual code updates shortening modernization and upgrade initiatives
- Seamless integration: Works within your existing development environment
As organizations continue to modernize their database infrastructure, services like Amazon Q Developer will play a crucial role in ensuring smooth, efficient migrations. By leveraging the power of AI to handle complex code transformations, developers can focus on adding value to their applications rather than getting bogged down in the intricacies of SQL dialect differences. We encourage you to try Amazon Q Developer using the Amazon Q User Guide for your next database migration project and experience firsthand the benefits of automated SQL code conversion.
About the Authors
