Enhancing Network Resilience with Istio on Amazon EKS
May 6, 2024This is the third blog post of our “Istio on EKS” series, where we will continue to explore Istio’s network resilience capabilities and demonstrate how to set up and configure these features on Amazon Elastic Kubernetes Service (Amazon EKS). Istio equips microservices with a robust set of features designed to maintain responsive and fault-tolerant communication, even in the face of unexpected events. From timeouts and retries to circuit breakers, rate limiting, and fault injection, Istio’s network resilience features provide a comprehensive safety net, ensuring that your applications continue to operate smoothly, minimizing downtime and enhancing the overall user experience. In this blog, we’ll explore the concept of network resilience with Istio and demonstrate how to set up and configure these vital features on Amazon EKS.
In our first blog, Getting started with Istio on EKS, we explained how to set up Istio on Amazon EKS. We covered core aspects such as Istio Gateway, Istio VirtualService, and observability with open source Kiali and Grafana. In the second blog Using Istio Traffic Management on Amazon EKS to Enhance User Experience, we explained traffic management strategies to accomplish sophisticated testing and deployment strategies, downtime reduction, and user experience enhancement for the communication among microservices.
Resilience refers to the ability of the service mesh to maintain stable and responsive communication between microservices, even in the face of failures, disruptions, or degraded network conditions. Istio provides several features and mechanisms to enhance network resiliency within a microservices architecture. These include timeouts, retries, circuit breaking, fault injection and rate limiting that collectively contribute to ensuring the reliability and robustness of the communication between services. The goal is to prevent cascading failures, improve fault tolerance, and maintain overall system performance in the presence of various network challenges.
Network Resilience with Istio on Amazon EKS
In this part of the blog series, we’ll focus on Istio’s practical network resilience features that prevent localized failures from spreading to other nodes. Resilience ensures the overall reliability of applications remains high.
- Fault Injection: Fault injection helps test failure scenarios and service-to-service communication by intentionally introducing errors in a controlled way. This helps find and fix problems before they cause outages in production, such as network outages, hardware failures, software failures, and human error.
- Timeouts: Timeouts are an important component of network resilience. They allow you to set a time limit for an operation or request to complete. If the operation or request does not complete within the specified time limit, it is considered a failure.
- Retries: Retries in Istio involves the automatic reattempt of a failed request to improve the resilience and availability of microservices-based applications.
- Circuit breaker: Circuit breaker serves as a resilience mechanism for microservices. It will prevent continuous retries to a failing service, preventing overload and facilitating graceful degradation.
- Rate Limiting: Rate limiting gives flexibility to apply customized throttling rules to avoid overloading services and restricting usage where necessary. This helps improve application stability and availability.
Deployment Architecture
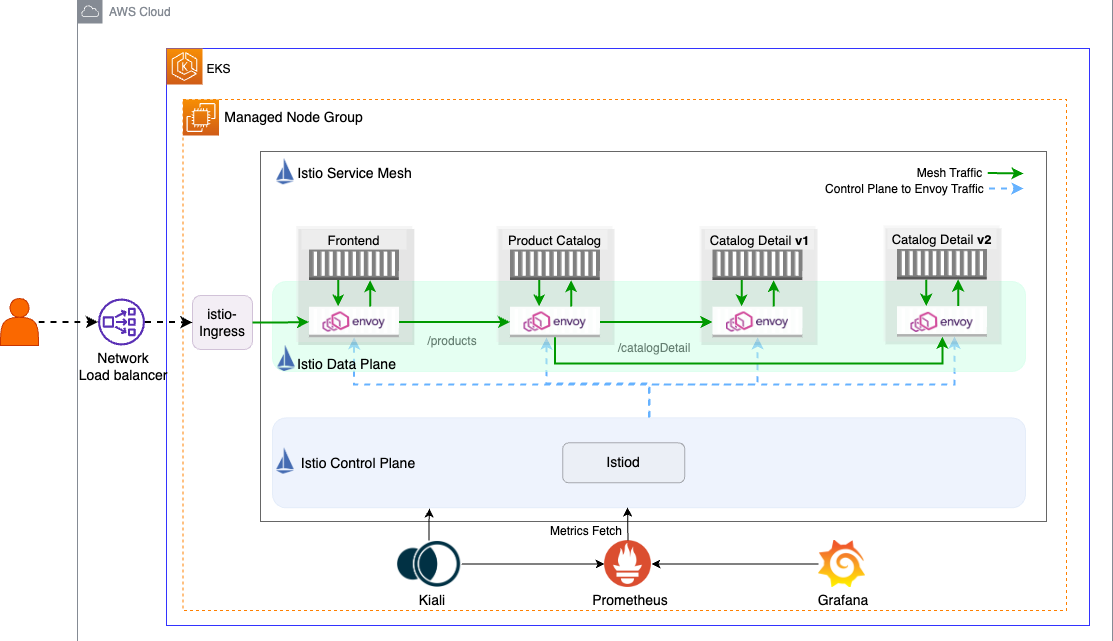
We’ll leverage the same microservices-based product catalog application that we used in our first blog Getting Started with Istio on EKS that will serve as our practical playground. This will allow us to explore Istio’s capabilities in a hands-on manner. The application is composed of three types of microservices: Frontend, Product Catalog, and Catalog Detail as shown in the Istio Data Plane in this diagram.

Prerequisites and Initial Setup
Before we proceed to the rest of this post, we need to make sure that the prerequisites are correctly installed. When complete, we will have an Amazon EKS cluster with Istio and the sample application configured.
First, clone the blog example repository:
Then we need to complete all the following steps. Note: These steps are from Module 1 – Getting Started that was used in the first Istio blog Getting started with Istio on EKS.
- Prerequisites – Install tools, set up Amazon EKS and Istio, configure istio-ingress and install Kiali using the Amazon EKS Istio Blueprints for Terraform that we used in the first blog.
- Deploy – Deploy Product Catalog application resources and basic Istio resources using Helm.
- Configure Kiali – Port forward to Kiali dashboard and Customize the view on Kiali Graph.
- Install
istioctland add it to the $PATH
NOTE: Do not proceed if you don’t get the result here using the following command:
Note: Do not execute the Destroy section in Module 1!
Initialize the Istio service mesh resources
The following command will create all the Istio resources required for the product catalog application. You can check the “Key Istio Components” explained in our previous blog Using Istio Traffic Management on Amazon EKS to Enhance User Experience
Network Resilience Use cases
Now we are going to explore various features in Istio that help manage network resilience. Throughout each section, we’ll provide step-by-step instructions on how to apply these features to your Istio service mesh. At the end of each section, we’ll also show you how to reset the environment, ensuring a clean slate before moving on to the next feature. By the end of this process, you’ll have a comprehensive overview of how Istio helps manage network resilience by providing features like fault injection, timeouts, retries, circuit breakers, and rate limiting.
Fault Injection
Fault injection in Istio is a powerful tool to validate and enhance the resiliency of your applications, helping prevent costly outages and disruptions by proactively identifying and addressing problems. This technique utilizes two types of faults, Delays and Aborts, both configured through a Virtual Service. Unlike other approaches that primarily target network-level disruptions, Istio allows fault injection at the application layer, enabling precise testing of specific HTTP error codes to yield more meaningful insights.
In practical usage, fault injection serves to assess applications under various conditions. This includes testing responses during sudden increases in demand by introducing delays and aborts, evaluating how applications handle database disruptions through simulated connection failures and slow responses, and assessing network connectivity in scenarios involving packet loss or network disconnections via delays and aborts.
Injecting Delay Fault into HTTP Requests
Delays are essential for fault injection, closely simulating timing failures akin to network latency increases or upstream service overload. This aids in assessing application responses to slow communication or response times, strengthening system resilience. In this section, we’ll provide a step-by-step guide to injecting delay faults into HTTP requests.
We will be updating the catalogdetail VirtualService for this use case as shown here:
In VirtualService, the fault field injects delays for traffic to catalogdetail service for an internal user. Delays can be fixed or percentage-based. The above config applies a 15-second delay to 100% of requests to catalogdetail.
Create this fault injection rule for delaying traffic to catalogdetail:
Test the delay by running a curl command against the catalogdetail service for the users named internal and external.
The output should be similar to what’s shown here. A 15-second delay is introduced for the ‘internal’ user as per the catalogdetail virtual service’s delay fault config.
Run the curl command for the user named external (could be any user other than internal.)
The output should be similar to what’s shown here. There should be no delay for ‘external’ user as the catalogdetail virtual service’s delay fault config only targets ‘internal’ users.
Now, to exit from the shell inside the frontend container first press Enter, then type ‘exit’ and press Enter once more.
By introducing a delay for catalogdetail service, delay is injected into the traffic before it reaches the service, affecting a specific user or set of users. Through intentional testing, we can effectively assess the application’s resiliency, conducting experiments within a defined user scope.
Injecting Abort Fault into HTTP Requests
Aborts are vital for fault injection, mimicking upstream service crash failures often seen as HTTP error codes or TCP connection issues. By introducing aborts into HTTP requests, we can replicate these scenarios, enabling comprehensive testing to bolster application resilience. In this section, we’ll provide a step-by-step guide to injecting abort faults into HTTP requests.
We will be updating the catalogdetail VirtualService for this use case as shown here:
In VirtualService, the fault field injects an abort for catalogdetail service traffic to the internal user. The httpStatus 500 means clients get a 500 Internal Server Error response.
Create this fault injection rule to abort traffic directed towards catalogdetail.
Test the abort by running a curl command against the catalogdetail service for the users named internal and external.
The output should be similar to what’s shown here. You should see HTTP 500 error (Abort) for the ‘internal’ user per catalogdetail virtual service’s abort fault config.
Run the curl command for the user named external (could be any user other than internal.)
The output should be similar to what’s shown here. You should see HTTP 200 success for the ‘external’ user as catalogdetail virtual service’s abort fault config targets only ‘internal’ users.
Now, to exit from the shell inside the frontend container first press Enter, then type ‘exit’ and press Enter once more.
By introducing an abort for the catalogdetail service, an HTTP abort fault is injected into the traffic before it reaches the service for a specific user or set of users. Through intentional testing, we can effectively assess the application’s resiliency, conducting experiments within a defined user scope.
Reset the environment
Reset the configuration to the initial state by running the following command from the fault-injection directory:
Timeouts
In Istio, timeouts refer to the maximum duration a service or proxy waits for a response from another service before marking the communication as failed. The timeouts help to manage and control the duration of requests, contributing to the overall reliability and performance of the microservices communication within the Istio service mesh.
To test the timeout functionality we will make a call from the productcatalog service to the catalogdetail service. We will be using the fault injection approach that we explored before to introduce delay in the catalogdetail service. Then we will add a timeout to the productcatalog service.
- Let’s apply the 5 second delay to the
catalogdetailvirtual service.
Test the delay by running a curl command against the productcatalog service from within the mesh.
If the delay configuration is applied correctly, the output should be similar to this:
2. Apply the timeout of 2 seconds to the productcatalog virtual service.
With a 2-second timeout set for the productcatalog service, any calls made to the catalogdetail service, which typically has a response time of approximately 5 seconds, will inevitably exceed the designated timeout threshold, resulting in triggered timeouts for those calls.
Test the timeout by running a curl command against the productcatalog service from within the mesh.
The output should be similar to this:

In conclusion, Istio’s timeouts feature enhances service resilience by managing the timing of requests between services in a microservices architecture. It prevents resource exhaustion by ensuring that resources are not held indefinitely while waiting for responses from downstream services. Timeout settings help isolate failures by quickly detecting and handling unresponsive downstream services, improving system health and availability.
Reset the environment
Reset the configuration to the initial state by running the following command from the timeouts-retries-circuitbreaking directory:
Retries
Retries in Istio involve the automatic re-attempt of a failed request to improve the resilience of the system. A retry setting specifies the maximum number of times an Envoy proxy attempts to connect to a service if the initial call fails. This helps handle transient failures, such as network glitches or temporary service unavailability.
To test the retries functionality we will make the following changes to the productcatalog VirtualService:
1. Add configuration for retries with 2 attempts to the productcatalog VirtualService.
2. Edit the productcatalog deployment to run a container that does nothing other than to sleep for 1 hour. To achieve this we make the following changes to the deployment:
-
- Change the
readinessProbeto run a simple commandecho hello. Since the command always succeeds, the container would immediately be ready. - Change the
livenessProbeto run a simple commandecho hello. Since the command always succeeds, the container is immediately marked to be live. - Add a
commandto the container that will cause the main process to sleep for 1 hour.
- Change the
To apply these changes, run the following command:
This assumes that you are currently in “istio-on-eks/modules/03-network-resiliency/timeouts-retries-circuitbreaking” folder
Enable debug mode for the envoy logs of the productcatalog service with the following command:
Note: If you get an error, then open another new terminal to execute the following command. Make sure istioctl is in the path and you are in this folder “istio-on-eks/modules/03-network-resiliency/timeouts-retries-circuitbreaking”
To see the retries functionality from the logs, execute the following command:
Open a new terminal and run the curl command against the productcatalog service from within the mesh by using the command here:
Now, you should see the retry attempts in the logs on your first terminal:
This diagram shows the Frontend envoy proxy trying to connect to the productcatalog VirtualService with 2 retry attempts after the initial call fails. If the request is unsuccessful after the retry attempts, this will be treated as an error and and it’s sent back to the Frontend service.

To conclude, the retry functionality operates as intended. The recorded ‘x-envoy-attempt-count’ of three includes the initial connection attempt to the service, followed by the two additional retry attempts, as defined in the configuration added to the productcatalog VirtualService.
Reset the environment
Reset the configuration to the initial state by running the following command from the timeouts-retries-circuitbreaking directory.
Circuit Breakers
Circuit breakers are another resilience feature provided by Istio’s Envoy proxies. Circuit breaker is a mechanism that boosts the resilience of a microservices based system by preventing continuous retries to a failing service. It helps avoid overwhelming a struggling service and enables the system to gracefully degrade when issues arise. When a predefined threshold of failures is reached, the circuit breaker activates and temporarily halts the request to the failing service to recover. Once a specified timeout elapses or the failure rate decreases then the circuit breaker resets, allowing the normal requests flow to resume.
Update the existing catalogdetail destination rule to apply circuit breaking configuration.
As part of the connectionPool settings, the service has a maximum limit on the number of connections, and Istio will queue any surplus connections beyond this limit. You can adjust this limit by modifying the value in the maxConnections field, which is set to 1 in the above configuration. Additionally, there is a maximum for pending requests to the service, and any exceeding pending requests will be declined. You have the flexibility to modify this limit by adjusting the value in the http1MaxPendingRequests field, which is set to 1 in the above configuration.
As part of the outlierDetection settings, Istio will detect any host that triggers a server error (5XX code) in the catalogdetail Envoy and eject the pod out of the load balancing pool for 3 minutes.
To test the circuit breaker feature we will use a load testing application called fortio. To do this we will run a pod with a single container based on the fortio image. Run the command here to create a fortio pod in the workshop namespace:
Now from within the fortio pod test out a single curl request to the catalogdetail service:
You can see the request succeed, as shown here:
Tripping the circuit breaker
We can start testing the circuit breaking functionality by generating traffic to the catalogdetail service with two concurrent connections (-c 2) and by sending a total of 20 requests (-n 20):
The output should be similar to this:
We notice that the majority of requests have been successful, with only a few exceptions. The istio-proxy does allow for some leeway.
Now re-run the same command by increasing the number of concurrent connections to 3 and number of calls to 30
The output should be similar to this:
As we increase the traffic towards the catalogdetail microservice we start to notice the circuit breaking functionality kicking in. We now notice that only 40% of the requests succeeded and the other 60%, as expected, were trapped by the circuit breaker.
Now, query the istio-proxy to see the statistics of the requests flagged for circuit breaking.
The output should be similar to this:
In summary, the output above reveals that the upstream_rq_pending_overflow parameter holds a value of 17. This indicates that 17 calls so far have been flagged for circuit breaking, providing clear evidence that our circuit breaker configuration for the catalogdetail DestinationRule has effectively functioned as intended.
Reset the environment
Delete the fortio pod using the following command and then run the same steps as in the Initial state setup to reset the environment.
Rate Limit
Local Rate Limiting in Istio allows you to control the rate of traffic for individual services or service versions within your cluster. This allows you to control the rate of requests for specific services or endpoints. Global Rate Limiting in Istio allows you to enforce rate limits across the entire mesh and/or for a specific gateway.
Global rate limiting uses a global gRPC rate limiting service, shared by all the services in the cluster, to enforce the rate limiting for the entire mesh. The rate-limiting service requires an external component, typically a Redis database. Local rate limiting can be used in conjunction with global rate limiting to reduce load on the global rate limiting service.
NOTE: This sub-module expects you to be in the rate-limit sub module under the 03-network-resiliency module of the git repo.
Local Rate Limiting
Applying the local rate limit is done by applying EnvoyFilter to an individual service within the application. In our example, we are going to be applying the limit to the prodcatalog service.
Looking into the contents of the local-ratelimit.yaml file:
- The HTTP_FILTER patch inserts the envoy.filters.http.local_ratelimit local envoy filter into the HTTP connection manager filter chain.
- The local rate limit filter’s token bucket is configured to allow 10 requests/min.
- The filter is also configured to add an x-local-rate-limit response header to requests that are blocked.
Apply Local Rate Limiting to the prodcatalog service:
To test the rate limiter in action, exec into the frontend pod and send requests to the prodcatalog service to trigger the rate limiter.
Since the 20 requests are sent in less than a minute, after the first 10 requests are accepted by the service you’ll start seeing HTTP 429 response codes from the service.
Successful requests will return the following output:
While rate limited requests will return the following output:
Similarly, if you run the same shell command without the -I flag, you’ll start seeing local_rate_limited responses for the requests that are rate limited. These rate limited requests will look something like this:
Global Rate Limiting
Applying Global Rate limiting to the Istio Service Mesh can be done by performing the following steps:
Step 1 – Setting up Global Rate Limit Service
To use the Global Rate Limit in our Istio service mesh we need a central global rate limit service that implements Envoy’s rate limit service protocol. This can be achieved by:
- Applying the Global Rate Limiting configuration for the Global Rate Limit service via the global-ratelimit-config.yaml ConfigMap:
In this file, rate limit requests to the / path are set to 5 requests/minute and all other requests are set to 100 requests/minute.
- Deploying the Global Rate Limit service with Redis via the global-ratelimit-service.yaml file.
This file has Deployment and Service definitions for:
- Central Rate Limit Service; and
- Redis
Step 2 – Enable the Global Rate Limit
Once the central rate limit service and redis is configured and deployed, Global Rate Limiting can be enabled and configured by applying two EnvoyFilters to the IngressGateway:
- The first EnvoyFilter defined in the filter-ratelimit.yaml file enables global rate limiting using Envoy’s global rate limit filter.
- The second EnvoyFilter defines the route configuration on which rate limiting will be applied. Looking at the filter-ratelimit-svc.yaml file, the configuration adds rate limit actions for any route from a virtual host.
To test the global rate limit in action, run the following command in a terminal session:
In the output you should notice that the first five requests will generate output similar to the one here:
And the last request should generate output similar to:
We see this behavior because of the global rate limiting that is in effect. It is only allowing a maximum of 5 requests/minute when the context-path is /.
Reset the environment
Execute the following command to remove all rate-limiting configurations and services:
Delete all rate limiting configurations and services
Clean up
To clean up the Amazon EKS environment and remove the services we deployed, please run the following commands:
NOTE: To further remove the Amazon EKS cluster with deployed Istio that you might have created in the prerequisite step, go to the Terraform Istio folder ($YOUR-PATH/terraform-aws-eks-blueprints/patterns/istio) and run the commands provided here.
Conclusion
In this blog post, we explored how Istio on Amazon EKS can enhance network resilience for microservices. By providing critical features like timeouts, retries, circuit breakers, rate limiting, and fault injection, Istio enables microservices to maintain responsive communication even when facing disruptions. As a result, Istio helps prevent localized failures from cascading and bringing down entire applications. Overall, Istio gives developers powerful tools to build reliability and robustness into microservices architectures. The service mesh creates a layer of infrastructure that adds resilience without changing application code.
As we conclude this post on network resilience, stay tuned for our next blog where we will dive deep into security with Istio in Amazon EKS. We have much more to explore when it comes to hardening and protecting microservices. Join us on this ongoing journey as we leverage Istio and Amazon EKS to create robust cloud native applications.
