How A/B Testing and Multi-Model Hosting Accelerate Generative AI Feature Development in Amazon Q
August 26, 2024Introduction
In the rapidly evolving landscape of Generative AI, the ability to deploy and iterate on features quickly and reliably is paramount. We, the Amazon Q Developer service team, relied on several offline and online testing methods, such as evaluating models on datasets, to gauge improvements. Once positive results are observed, features were rolled out to production, introducing a delay until the change affected 100% of customers.
This blog post delves into the impact of A/B testing and Multi-Model hosting on deploying Generative AI features. By leveraging these powerful techniques, our team has been able to significantly accelerate the pace of experimentation, iteration, and deployment. We have not only streamlined our development process but also gained valuable insights into model performance, user preferences, and the potential impact of new features. This data-driven approach has allowed us to make informed decisions, continuously refine our models, and provide a user experience that resonates with our customers
What is A/B Testing?
A/B testing is a controlled experiment, and a widely adopted practice in the tech industry. It involves simultaneously deploying multiple variants of a product or feature to distinct user segments. In the context of Amazon Q Developer, the service team leverages A/B testing to evaluate the impact of new model variants on the developer experience. This helps in gathering real-world feedback from a subset of users before rolling out changes to the entire user base.
- Control group: Developers in the control group continue to receive the base Amazon Q Developer experience, serving as the benchmark against which changes are measured.
- Treatment group: Developers in the treatment group are exposed to the new model variant or feature, providing a contrasting experience to the control group.
To run an experiment, we take a random subset of developers and evenly split it into two groups: The control group continues to receive the base Amazon Q Developer experience, while the treatment group receives a different experience.
By carefully analyzing user interactions and telemetry metrics of the control group and comparing them to those from the treatment group, we can make informed decisions about which variant performs better, ultimately shaping the direction of future releases.
How do we split the users?
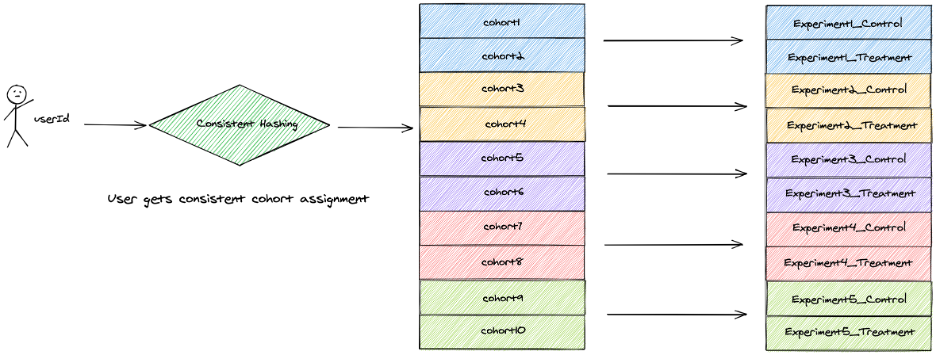
Whenever a user request is received, we perform consistent hashing on the user identity and assign the user to a cohort. Irrespective on which machine the algorithm runs, the user will be assigned the same cohort. This means that we can scale horizontally – user A’s request can be served by any machine and user A will always be assigned to group A from the beginning to the end of the experiment.
Individuals in the two groups are, on average, balanced on all dimensions that will be meaningful to the test. This means that we do not expose a cohort to have more than one experiment at any given time. This enables us to conduct multivariate experiments where one experiment does not impact the result of another.

The above diagram illustrates the process of user assignment to cohorts in a system conducting multiple parallel A/B experiments.
How do we enable segmentation?
For some A/B experiments, we want to perform A/B experiments for users matching certain criteria. Assume we want to exclusively target Amazon Q Developer customers using the Visual Studio Code Integrated Development Environment (IDE). For such scenarios, we perform cohort allocation only for users who meet the criteria. In this example, we would divide a subset of Visual Studio Code IDE users into control and treatment cohorts.
How do we route the traffic between different models ?
Early on, we realized that we will need to host hundreds of models. To achieve this, we run multiple Amazon Elastic Container Service (Amazon ECS) clusters to host different models. We leverage Application Load Balancer’s path based routing to route traffic to the various models.

The above diagram depicts how Application Load Balancer redirects traffic to various models based on path-based routing. Where path1 is routing to control model and path2 is routing to treatment model 1 etc.
How do we enable different IDE experiences for different groups?
The IDE plugin polls the service endpoint asking if the developer belongs to the control or treatment group. Based on the response the user will be served the control or treatment experience.

The above diagram depicts how the IDE plugin provides different experience based on control or treatment group.
How do we ingest data?
From the plugin, we publish telemetry metrics to our data plane. We honor opt-out settings of our users. If the user is opted-out, we do not store their data. In the data plane, we check the cohort of the caller. We publish telemetry metrics with cohort metadata to Amazon Data Firehose, which delivers the data to an Amazon OpenSearch Serverless destination.

The above diagram depicts how metrics are captured via the data plane into Amazon OpenSearch Serverless.
How do we analyze the data?
We publish the aggregated metrics to OpenSearch Serverless. We leverage OpenSearch Serverless to ingest and index various metrics to compare and contrast between control and treatment cohorts. We enable filtering based on metadata such as programming language and IDE.
Additionally, we publish data and metadata to a data lake to view, query and analyze the data securely using Jupyter Notebooks and dashboards. This enables our scientists and engineers to perform deeper analysis.
Conclusion
This post has focused on challenges Generative AI services face when it comes to fast experimentation cycles, the basics of A/B testing and the A/B testing capabilities built by the Amazon Q Developer service team to enable multi-variate service and client-side experimentation. We can gain valuable insights into the effectiveness of the new model variants on the developer experience within Amazon Q Developer. Through rigorous experimentation and data-driven decision-making, we can empower teams to iterate, innovate, and deliver optimal solutions that resonate with the developer community.
We hope you are as excited as us about the opportunities with Generative AI! Give Amazon Q Developer and Amazon Q Developer Customization a try today:
Amazon Q Developer Free Tier: https://aws.amazon.com/q/developer/#Getting_started/
Amazon Q Developer Customization: https://docs.aws.amazon.com/amazonq/latest/qdeveloper-ug/customizations.html
About the authors
