How Traveloka Uses Backstage as an API Developer Portal for Amazon API Gateway
May 31, 2023In this post, you will learn how Amazon Web Services (AWS) customer, Traveloka, one of the largest online travel companies in Southeast Asia, uses Backstage as the developer portal for APIs hosted on Amazon API Gateway (API Gateway).
API Gateway is a fully managed service that creates RESTful and WebSocket APIs. An API developer portal is a bridge between API publishers and consumers. Consumers use API contracts and documentation published by producers to build client applications.
Prior to Traveloka implementing Backstage, each service team documented APIs in their own way. As a result, developers lost time going back and forth with service teams to build integrations.
With Backstage, developers centralize and standardize API contracts and documentation to accelerate development and avoid bottlenecks.
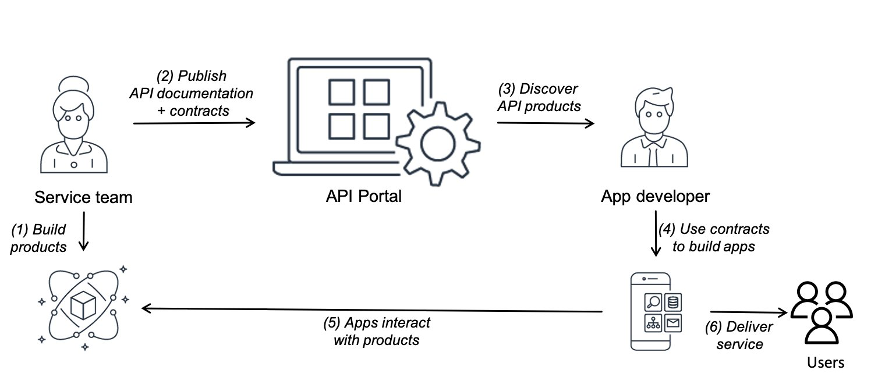
API portal
Modern application design, such as a microservices architecture, is highly modular. This increases the number of integrations you need to build. APIs are a common way to expose microservices while abstracting away implementation details.
As the number of services and teams supporting them grow, developers find it difficult to discover APIs and build integrations. APIs also simplify how third parties integrate with your service. An API portal consolidates API documentation in a central place. This image shows the role of an API portal:

Figure 1: Role of an API portal
There are multiple ways to build an API portal for API Gateway. One option is to integrate AWS Partner solutions like ReadMe with API Gateway. Software as a Service (SaaS) solutions like ReadMe let you get started quickly and reduce operational overhead.
But customers who prefer a highly configurable set up or open source solutions choose to build their own. Traveloka chose to host Backstage on Amazon Elastic Kubernetes Service (Amazon EKS) for the portal, in part because the company was already using Backstage as its developer portal.
Backstage
Backstage is an open source framework for developer portals under the Cloud Native Computing Foundation (CNCF). The software catalog, at the heart of Backstage, consists of entities that describe software components such as services, APIs, CI/CD pipelines, and documentation.
Service owners can define entities using metadata YAML files, and developers can use the interface to discover services.
This image shows the API portal:

Figure 2: Example API portal on Backstage
Backstage has a frontend and backend component. It stores state in a relational database. You can customize Backstage using YAML configuration files. It integrates with cloud providers and other external systems using plugins.
For instance, you can use Amazon Simple Storage Service (Amazon S3) as the source of entities that will be ingested into the catalog. This image shows a common production deployment approach using containers:

Figure 3: Backstage architecture
Backstage at Traveloka
The majority of services at Traveloka are written in Java and run on Amazon EKS. Backstage is managed by the cloud infrastructure team in a separate AWS account. This team provides a Java SDK, called generator, that service teams use to onboard their services to Backstage.
This generator abstracts away Backstage integration details from service developers and generates the YAML entity files automatically from application configuration at run time. This image shows the Backstage API portal deployment at Traveloka:

Figure 4: API portal on Backstage at Traveloka
- Service teams integrate the Backstage generator SDK with their applications.
- Changes kick off the CI/CD pipeline.
- The pipeline runs tests and deploys the service.
- The generator creates or updates an API entity definition in an Amazon S3 bucket.
- The Amazon S3 discovery plugin installed on Backstage syncs the catalog from the Amazon S3 bucket.
- Developers authenticate with GitHub apps to access the portal.
The generator runs on service start up post deployment. First, it generates the Open API specification (OAS) for the API if needed. Not all services at Traveloka have standardized on OAS yet. Second, it uses runtime application configuration such as a service name, environment, and custom tags to generate the metadata YAML files. It copies it to an Amazon S3 bucket in the Backstage AWS account using a cross-account AWS Identity and Access Management (IAM) role.
The generator is non-blocking and errors do not affect the service. Generating documentation from a running application guarantees accurate representation of service capabilities. It handles cases where API Gateway is only a proxy and application framework manages routing. The AWS S3 discovery plugin installed on Backstage crawls the Amazon S3 bucket and registers new and updated entities.
Backstage deployment is automated with a CI/CD pipeline. Development and production environments are hosted on separate Amazon EKS clusters. Services are always onboarded to the production cluster. The infrastructure team uses the development cluster to test new plugins, features, and version upgrades before deploying them to production.
A two-person team manages the Backstage infrastructure. Another two-person team builds and maintains the SDK and helps service teams onboard.
Since the project began in June 2022, Traveloka has onboarded 204 services in Q1 2023 and plans to onboard 600 more in Q2 2023.
We have seen how Traveloka automates API onboarding to Backstage dynamically based on runtime configurations. Alternately, you can generate and update entity definitions as part of your API CI/CD pipeline. This is more straightforward to do if you do not have any dependency on runtime configuration for your application.
Solution overview
In this post, we will run Backstage locally as an API portal. Amazon S3 is used as a source of entities that will be ingested into the catalog. State is tracked in a SQLite in-memory database.
Prerequisites
- Configuration of AWS Command Line Interface (AWS CLI) v2.
- Prerequisites for creating the Backstage app:
- Access to a Unix-based operating system, such as Linux, MacOS or Windows Subsystem for Linux.
- An account with elevated rights to install the dependencies.
- Installation of curl or wget.
- Access to Node.js Active LTS Release.
- Installation of yarn (you will need to use Yarn classic to create a new project, but it can then be migrated to Yarn 3)/
- Installation of docker
- Installation of git.
How to deploy the solution:
1. Create Backstage app.
2. Configure Amazon S3 as catalog location.
3. Upload API definition to Amazon S3 and test portal.
Step 1: Create Backstage app
Create a working directory for the code.
mkdir backstage-api-portal-blog
cd backstage-api-portal-blog
We will use npm to create the Backstage app. When prompted for the app name, enter api-portal. This will take a few minutes.
npx @backstage/create-app
Use yarn to run the app.
cd api-portal && yarn dev
Access your Backstage portal at http://localhost:3000. This image shows a sample catalog deployed:

Figure 5: Backstage running locally
Step 2: Configure Amazon S3 as catalog location
There are two steps to set up the Amazon S3 integration. You need to configure the Amazon S3 entity provider in app-config.yaml, and install the plugin.
Step 2.1: Configure Amazon S3 entity provider
Update the catalog providers section in api-portal/app-config.yaml to refer to the Amazon S3 bucket you wish to use as catalog. Create a new bucket using the command below. Replace sample-bucket with a unique name.
aws s3 mb s3://sample-bucket
You can also use an existing bucket. Replace the catalog section, line 73 through the end of the file, with the following code:
Step 2.2: Install the AWS catalog plugin
Run this command from the Backstage root folder, api-portal, to install the AWS catalog plugin:
yarn add --cwd packages/backend @backstage/plugin-catalog-backend-module-aws
Replace the content of api-portal/packages/backend/src/plugins/catalog.ts with the following code:
Step 3: Upload API definition to Amazon S3 and test portal
Create an API kind definition for the Swagger PetStore REST API. Save the following code in the file pet-store-api.yaml.
Copy this file to Amazon S3. Replace the bucket name and prefix with the ones you specified in step 2.1.
aws s3 cp pet-store-api.yaml s3://sample-bucket/backstage-api-blog/pet-store-api.yaml
To allow testing the API directly from the portal, Backstage must trust the domain swagger.io first. To activate this, open api-portal/app-config.yaml. Allow reading from swagger.io in the backend configuration section starting on line 8. Add this reading config:
If you have the portal running, restart it with Ctrl+C followed by yarn dev to pick the configuration change. You do not have to restart to pick up new entities or updates to existing ones in the Amazon S3 bucket.
Now when you navigate to the API section, you will see the PetStore API. Select the API name and navigate to the DEFINITION tab. This image shows the API documentation:

Figure 6: PetStore API documentation
Look for the GET /pet/findByStatus resource and expand the definition. This image shows the resource documentation:

Figure 7: PetStore API /pet/findByStatus resource documentation
Choose Try it out, then select available for status, followed by Execute, as shown in this image:

Figure 8: Test PetStore API /pet/findByStatus resource
You will get a status code of 200 and a list of available pets.
This concludes the steps to test the API portal with Backstage locally. Refer to the instructions for host build from the Backstage documentation to containerize the Backstage app for production deployment.
Cleanup
Delete the folder created for the Backstage app and the working folder. Run the following command from the working folder, backstage-api-portal-blog:
rm -rf api-portal && cd .. && rmdir backstage-api-portal-blog
Delete the API definition from the Amazon S3 bucket.
aws s3 rm s3://sample-bucket/backstage-api-blog/pet-store-api.yaml
Delete the Amazon S3 bucket.
aws s3 rb s3://sample-bucket
Conclusion
In this blog, we have shown you how to use Backstage to build an API portal. API portals are important to simplify the developer experience of discovering API products and building integrations.
Backstage addresses this capability when you host APIs on API Gateway on AWS. For production deployment, the containerized Backstage application can be deployed to either Amazon Elastic Container Service (Amazon ECS) or Amazon EKS.
For Amazon ECS, refer to the sample code for deploying Backstage using AWS Fargate and Amazon Aurora Postgres. For Amazon EKS, the Backstage Helm chart is an easy way to get started.
Visit the API Gateway pattern collection on Serverlessland to learn more on designing REST API integrations on AWS.
