How Zomato Boosted Performance 25% and Cut Compute Cost 30% Migrating Trino and Druid Workloads to AWS Graviton
April 25, 2023Zomato is an India-based restaurant aggregator, food delivery, dining-out company with over 350,000 listed restaurants across more than 1,000 cities in India. The company relies heavily on data analytics to enrich the customer experience and improve business efficiency. Zomato’s engineering and product teams use data insights to refine their platform’s restaurant and cuisine recommendations, improve the accuracy of waiting times at restaurants, speed up the matching of delivery partners and improve overall food delivery process.
At Zomato, different teams have different requirements for data discovery based upon their business functions. For example, number of orders placed in specific area required by a city lead team, queries resolved per minute required by customer support team or most searched dishes on special events or days by marketing and other teams. Zomato’s Data Platform team is responsible for building and maintaining a reliable platform which serves these data insights to all business units.
Zomato’s Data Platform is powered by AWS services including Amazon EMR, Amazon Aurora MySQL-Compatible Edition and Amazon DynamoDB along with open source software Trino (formerly PrestoSQL) and Apache Druid for serving the previously mentioned business metrics to different teams. Trino clusters process over 250K queries by scanning 2PB of data and Apache Druid ingests over 20 billion events and serves 8 million queries every week. To deliver performance at Zomato scale, these massively parallel systems utilize horizontal scaling of nodes running on Amazon Elastic Compute Cloud (Amazon EC2) instances in their clusters on AWS. Performance of both these data platform components is critical to support all business functions reliably and efficiently in Zomato. To improve performance in a cost-effective manner, Zomato migrated these Trino and Druid workloads onto AWS Graviton-based Amazon EC2 instances.
Graviton-based EC2 instances are powered by Arm-based AWS Graviton processors. They deliver up to 40% better price performance than comparable x86-based Amazon EC2 instances. CPU and Memory intensive Java-based applications including Trino and Druid are suitable candidates for AWS Graviton based instances to optimize price-performance, as Java is well supported and generally performant out-of-the-box on arm64.
In this blog, we will walk you through an overview of Trino and Druid, how they fit into the overall Data Platform architecture and migration journey onto AWS Graviton based instances for these workloads. We will also cover challenges faced during migration, how Zomato team overcame those challenges, business gains in terms of cost savings and better performance along with future plans of Zomato on Graviton adoption for more workloads.
Trino overview
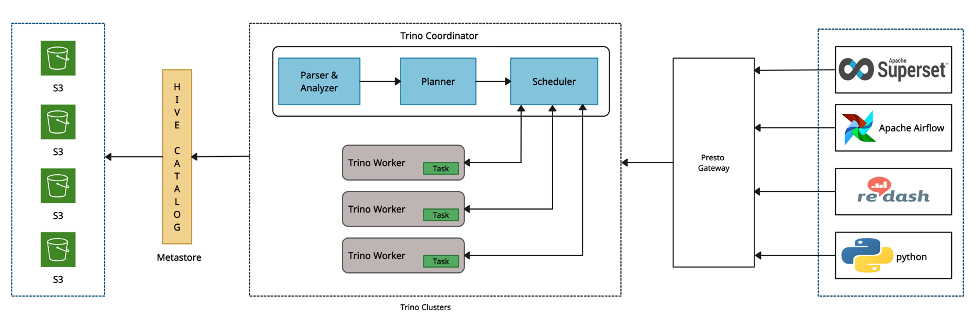
Trino is a fast, distributed SQL query engine for querying petabyte scale data, implementing massively parallel processing (MPP) architecture. It was designed as an alternative to tools that query Apache Hadoop Distributed File System (HDFS) using pipelines of MapReduce jobs, such as Apache Hive or Apache Pig, but Trino is not limited to querying HDFS only. It has been extended to operate over a multitude of data sources, including Amazon Simple Storage Service (Amazon S3), traditional relational databases and distributed data stores including Apache Cassandra, Apache Druid, MongoDB and more. When Trino executes a query, it does so by breaking up the execution into a hierarchy of stages, which are implemented as a series of tasks distributed over a network of Trino workers. This reduces end-to-end latency and makes Trino a fast tool for ad hoc data exploration over very large data sets.

Figure 1 – Trino architecture overview
Trino coordinator is responsible for parsing statements, planning queries, and managing Trino worker nodes. Every Trino installation must have a coordinator alongside one or more Trino workers. Client applications including Apache Superset and Redash connect to the coordinator via Presto Gateway to submit statements for execution. The coordinator creates a logical model of a query involving a series of stages, which is then translated into a series of connected tasks running on a cluster of Trino workers. Presto Gateway acts as a proxy/load-balancer for multiple Trino clusters.
Druid overview
Apache Druid is a real-time database to power modern analytics applications for use cases where real-time ingest, fast query performance and high uptime are important. Druid processes are deployed on three types of server nodes: Master nodes govern data availability and ingestion, Query nodes accept queries, execute them across the system, and return the results and Data nodes ingest and store queryable data. Broker processes receive queries from external clients and forward those queries to Data servers. Historicals are the workhorses that handle storage and querying on “historical” data. MiddleManager processes handle ingestion of new data into the cluster. Please refer here to learn more on detailed Druid architecture design.

Figure 2 – Druid architecture overview
Zomato’s Data Platform Architecture on AWS

Figure 3 – Zomato’s Data Platform landscape on AWS
Zomato’s Data Platform covers data ingestion, storage, distributed processing (enrichment and enhancement), batch and real-time data pipelines unification and a robust consumption layer, through which petabytes of data is queried daily for ad-hoc and near real-time analytics. In this section, we will explain the data flow of pipelines serving data to Trino and Druid clusters in the overall Data Platform architecture.
Data Pipeline-1: Amazon Aurora MySQL-Compatible database is used to store data by various microservices at Zomato. Apache Sqoop on Amazon EMR run Extract, Transform, Load (ETL) jobs at scheduled intervals to fetch data from Aurora MySQL-Compatible to transfer it to Amazon S3 in the Optimized Row Columnar (ORC) format, which is then queried by Trino clusters.
Data Pipeline-2: Debezium Kafka connector deployed on Amazon Elastic Container Service (Amazon ECS) acts as producer and continuously polls data from Aurora MySQL-Compatible database. On detecting changes in the data, it identifies the change type and publishes the change data event to Apache Kafka in Avro format. Apache Flink on Amazon EMR consumes data from Kafka topic, performs data enrichment and transformation and writes it in ORC format in Iceberg tables on Amazon S3. Trino clusters then query data from Amazon S3.
Data Pipeline-3: Moving away from other databases, Zomato had decided to go serverless with Amazon DynamoDB because of its high performance (single-digit millisecond latency), request rate (millions per second), extreme scale as per Zomato peak expectations, economics (pay as you go) and data volume (TB, PB, EB) for their business-critical apps including Food Cart, Product Catalog and Customer preferences. DynamoDB streams publish data from these apps to Amazon S3 in JSON format to serve this data pipeline. Apache Spark on Amazon EMR reads JSON data, performs transformations including conversion into ORC format and writes data back to Amazon S3 which is used by Trino clusters for querying.
Data Pipeline-4: Zomato’s core business applications serving end users include microservices, web and mobile applications. To get near real-time insights from these core applications is critical to serve customers and win their trust continuously. Services use a custom SDK developed by data platform team to publish events to the Apache Kafka topic. Then, two downstream data pipelines consume these application events available on Kafka via Apache Flink on Amazon EMR. Flink performs data conversion into ORC format and publishes data to Amazon S3 and in a parallel data pipeline, Flink also publishes enriched data onto another Kafka topic, which further serves data to an Apache Druid cluster deployed on Amazon EC2 instances.
Performance requirements for querying at scale
All of the described data pipelines ingest data into an Amazon S3 based data lake, which is then leveraged by three types of Trino clusters – Ad-hoc clusters for ad-hoc query use cases, with a maximum query runtime of 20 minutes, ETL clusters for creating materialized views to enhance performance of dashboard queries, and Reporting clusters to run queries for dashboards with various Key Performance Indicators (KPIs), with query runtime upto 3 minutes. ETL queries are run via Apache Airflow with a built-in query retry mechanism and a runtime of up to 3 hours.
Druid is used to serve two types of queries: computing aggregated metrics based on recent events and comparing aggregated metrics to historical data. For example, how is a specific metric in the current hour compared to the same last week. Depending on the use case, the service level objective for Druid query response time ranges from a few milliseconds to a few seconds.
Graviton migration of Druid cluster
Zomato first moved Druid nodes to AWS Graviton based instances in their test cluster environment to determine query performance. Nodes running brokers and middle-managers were moved from R5 to R6g instances and nodes running historicals were migrated from i3 to R6gd instances. Zomato logged real-world queries from their production cluster and replayed them in their test cluster to validate the performance. Post validation, Zomato saw significant performance gains and reduced cost:
Performance gains
For queries in Druid, performance was measured using typical business hours (12:00 to 22:00 Hours) load of 14K queries, as shown here, where p99 query runtime reduced by 25%.

Figure 4 – Overall Druid query performance (Intel x86-64 vs. AWS Graviton)
Also, query performance improvement on the historical nodes of the Druid cluster are shown here, where p95 query runtime reduced by 66%.

Figure 5 –Query performance on Druid Historicals (Intel x86-64 vs. AWS Graviton)
Under peak load during business hours (12:00 to 22:00 Hours as shown in the provided graph), with increasingly loaded CPUs, Graviton based instances demonstrated close to linear performance resulting in better query runtime than equivalent Intel x86 based instances. This provided headroom to Zomato to reduce their overall node count in the Druid cluster for serving the same peak load query traffic.

Figure 6 – CPU utilization (Intel x86-64 vs. AWS Graviton)
Cost savings
A Cost comparison of Intel x86 vs. AWS Graviton based instances running Druid in a test environment along with the number, instance types and hourly On-demand prices in the Singapore region is shown here. There are cost savings of ~24% running the same number of Graviton based instances. Further, Druid cluster auto scales in production environment based upon performance metrics, so average cost savings with Graviton based instances are even higher at ~30% due to better performance.

Figure 7 – Cost savings analysis (Intel x86-64 vs. AWS Graviton)
Graviton migration of Trino clusters
Zomato also moved their Trino cluster in their test environment to AWS Graviton based instances and monitored query performance for different short and long-running queries. As shown here, mean wall (elapsed) time value for different Trino queries is lower on AWS Graviton instances than equivalent Intel x86 based instances, for most of the queries (lower is better).

Figure 8 – Mean Wall Time for Trino queries (Intel x86-64 vs. AWS Graviton)
Also, p99 query runtime reduced by ~33% after migrating the Trino cluster to AWS Graviton instances for a typical business day’s (7am – 7pm) mixed query load with ~15K queries.

Figure 9 –Query performance for a typical day (7am -7pm) load
Zomato’s team further optimized overall Trino query performance by enhancing Advanced Encryption Standard (AES) performance on Graviton for TLS negotiation with Amazon S3. It was achieved by enabling -XX:+UnlockDiagnosticVMOptions and -XX:+UseAESCTRIntrinsics in extra JVM flags. As shown here, mean CPU time for queries is lower after enabling extra JVM flags, for most of the queries.

Figure 10 –Query performance after enabling extra JVM options with Graviton instances
Migration challenges and approach
Zomato team is using Trino version 359 and multi-arch or ARM64-compatible docker image for this Trino version was not available. As the team wanted to migrate their Trino cluster to Graviton based instances with minimal engineering efforts and time, they backported the Trino multi-arch supported UBI8 based Docker image to their Trino version 359. This approach allowed faster adoption of Graviton based instances, eliminating the heavy lift of upgrading, testing and benchmarking the workload on a newer Trino version.
Next Steps
Zomato has already migrated AWS managed services including Amazon EMR and Amazon Aurora MySQL-Compatible database to AWS Graviton based instances. With the successful migration of two main open source software components (Trino and Druid) of their data platform to AWS Graviton with visible and immediate price-performance gains, the Zomato team plans to replicate that success with other open source applications running on Amazon EC2 including Apache Kafka, Apache Pinot, etc.
Conclusion
This post demonstrated the price/performance benefits of adopting AWS Graviton based instances for high throughput, near real-time big data analytics workloads running on Java-based, open source Apache Druid and Trino applications. Overall, Zomato reduced the cost of its Amazon EC2 usage by 30%, while improving performance for both time-critical and ad-hoc querying by as much as 25%. Due to better performance, Zomato was also able to right size compute footprint for these workloads on a smaller number of Amazon EC2 instances, with peak capacity of Apache Druid and Trino clusters reduced by 25% and 20% respectively.
Zomato migrated these open source software applications faster by quickly implementing customizations needed for optimum performance and compatibility with Graviton based instances. Zomato’s mission is “better food for more people” and Graviton adoption is helping with this mission by providing a more sustainable, performant, and cost-effective compute platform on AWS. This is certainly a “food for thought” for customers looking forward to improve price-performance and sustainability for their business-critical workloads running on Open Source Software (OSS).
