Kubernetes Multi-Cluster Service Discovery using Open Source AWS Cloud Map MCS Controller
June 22, 2023With its implementation of the cluster construct, Kubernetes has streamlined the ability to schedule workloads across a collection of virtual machines (VMs) or nodes. Declarative configuration, immutability, auto-scaling, and self-healing have vastly improved the paradigm of workload management within the cluster. As a result, teams can now move at increasing velocities.
As the rate of Kubernetes adoption continues to increase, there has been a corresponding increase in the number of use cases that require workloads to break through the perimeter of the single cluster construct. A lot of progress has been made in open source tooling to help manage multi-cluster workloads, including the upstream Kubernetes Multi-Cluster Services API (mcs-api), and the open source Amazon Web Services (AWS) Cloud Map MCS Controller (MCS-Controller).
This blog post will provide an overview of Kubernetes multi-cluster workload management, the mcs-api, and the MCS-Controller which is the AWS open source implementation of the mcs-api.
This post also provides comprehensive instruction on how to make a Kubernetes service automatically discoverable and accessible across multiple clusters using the MCS-Controller.
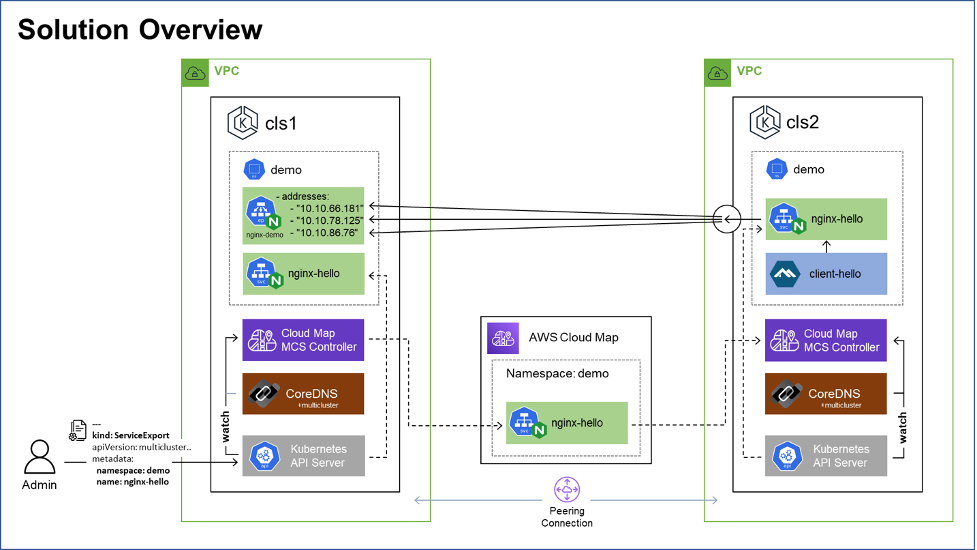
Image one here illustrates the demonstrated solution, where example service, “nginx-hello,” deployed to Kubernetes cluster, “cls1,” is both discoverable and consumable from Kubernetes cluster “cls2,” using the MCS-Controller.
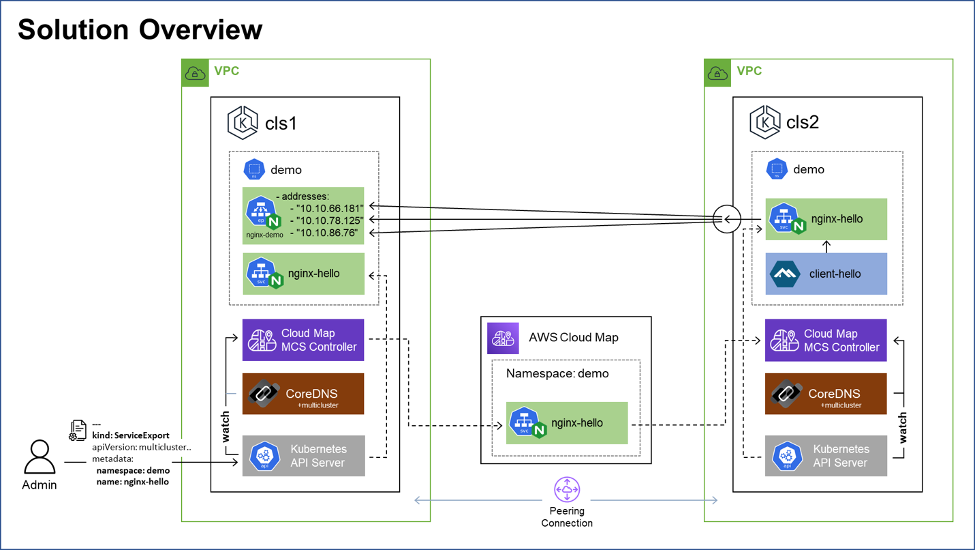
Image one: AWS Cloud Map MCS-Controller solution deployment overview diagram
Background
The requirements concerning workload location/proximity, isolation, and reliability have been the primary catalyst for the emergence of deployment scenarios where a single logical workload spans multiple Kubernetes clusters:
- Location: Location-based concerns include the following:
- Network latency requirements: For example, bringing the application as close to users as possible.
- Data gravity requirements: For example, bringing elements of the application as close to fixed data sources as possible.
- Jurisdiction-based requirements: For example, data residency limitations imposed by governing bodies.
- Isolation: Isolation-based concerns include the following:
- Performance: For example, reduction in “noisy-neighbor” influence in mixed workload clusters.
- Environmental: For example, by staged or sandboxed workload constructs, such as “dev,” “test,” and “prod” environments).
- Security: For example, separating untrusted code or sensitive data.
- Organizational: For example, teams falling under different business units or management domains.
- Cost-based: For example, teams being subject to separate budgetary constraints.
- Reliability: Reliability-based concerns include the following:
- Blast radius and infrastructure diversity: For example, preventing an application-based issue or underlying infrastructure issue in one cluster or provider zone from impacting the entire solution.
- Sand scale-based: For example, the possibility that the workload may outgrow a single cluster.
Multi-cluster application architectures tend to be designed using either a replicated or group-by-service pattern. In a replicated pattern, each participating cluster runs a full copy of each given application. Alternatively, with a group-by-service pattern the services of a single application or system are split or divided among multiple clusters.
When it comes to Kubernetes configuration (and the surrounding infrastructure) supporting a given multi-cluster application architecture, the space has evolved over time to include a number of approaches. Implementations tend to draw on a combination of components at various levels of the stack. Generally speaking, they also vary in terms of the weight or complexity of the implementation, number and scope of features offered, and the associated management overhead.
These approaches loosely fit into two main categories:
Network-centric approaches: Approaches that focus on network interconnection tooling to implement connectivity between clusters to facilitate cross-cluster application communication. The various network-centric approaches include those that are tightly coupled with the Container Network Interface (CNI) (for example, Cillium Service Mesh), as well as more CNI-agnostic implementations, such as Submariner and Skupper.
Service mesh implementations also fall into the network-centric category, and these include Istio’s multicluster support, Linkerd service mirroring, Kuma from Kong, AWS App Mesh, and Consul’s Mesh Gateway. There are also various multi-cluster ingress approaches, as well as virtual-kubelet-based approaches, including Admiralty, Tensile-kube, and Liqo.
Kubernetes-centric approaches: Approaches that focus on supporting and extending the core Kubernetes primitives to support multi-cluster use cases. These approaches fall under the stewardship of the Kubernetes Multicluster Special Interest Group, whose charter is focused on designing, implementing, and maintaining APIs, tools, and documentation related to multi-cluster administration and application management. Subprojects include the following:
- kubefed (Kubernetes Cluster Federation): This implements a mechanism to coordinate the configuration of multiple Kubernetes clusters from a single set of APIs in a hosting cluster. kubefed is considered to be foundational for more complex multi-cluster use cases, such as deploying multi-geo applications and disaster recovery.
- work-api (Multi-Cluster Work API): This aims to group a set of Kubernetes API resources to be applied to one or multiple clusters together as a concept of “work” or “workload,” for the purpose of multi-cluster workload lifecycle management.
- mcs-api (Multi-Cluster Services API): This implements an API specification to extend the single-cluster bounded Kubernetes service concept to function across multiple clusters.
Multi-cluster Services API
Kubernetes’ familiar Services object lets you discover and access services within the boundary of a single Kubernetes cluster. The mcs-api implements a Kubernetes-native extension to the Service API, extending the scope of the service resource concept beyond the cluster boundary. This provides a mechanism to weave multiple clusters together using standard (and familiar) DNS-based service discovery.
KEP-1645: Multi-Cluster Services API provides the formal description of the Multi-Cluster Service API. KEP-1645 doesn’t define a complete implementation; it serves to define how an implementation should behave. At the time of writing this, the mcs-api version is multicluster.k8s.io/v1alpha1.
The primary deployment scenarios covered by the mcs-api include the following:
- Different services each deployed to separate clusters: I have two clusters, each running different services managed by different teams, where services from one team depend on services from the other team. I want to ensure that a service from one team can discover a service from the other team (through DNS resolving to VIP)—regardless of the cluster that they reside in. In addition, I want to make sure that if the dependent service is migrated to another cluster, the dependence is not impacted.
- Single service deployed to multiple clusters: I have deployed my stateless service to multiple clusters for redundancy or scale. Now I want to propagate topologically-aware service endpoints (local, regional, global) to all clusters, so that other services in my clusters can access instances of this service in priority order, based on availability and locality.
The mcs-api is able to support these use cases through the described properties of a ClusterSet, which is a group of clusters with a high degree of mutual trust and shared ownership that share services among themselves. Additionally, the mcs-api supports two additional API objects: ServiceExport and ServiceImport.
Services are not visible to other clusters in the ClusterSet by default. Instead, they must be explicitly marked for export by the user. Creating a ServiceExport object for a given service specifies that the service should be exposed across all clusters in the ClusterSet. The mcs-api implementation (typically a controller) will automatically generate a corresponding ServiceImport object. This serves as the in-cluster representation of a multi-cluster service) in each importing cluster, allowing consumer workloads to locate and consume the exported service.
Kubernetes DNS-Based Multicluster Service Discovery Specification facilitates the DNS-based service discovery for ServiceImport objects. This extends the standard Kubernetes DNS paradigms by implementing records named by service and namespace for ServiceImport objects, but as differentiated from regular in-cluster DNS service names by using the special zone .clusterset.local.
In other words, when a ServiceExport is created, this will cause a Fully Qualified Domain Name (FQDN) for the multi-cluster service to become available from within the ClusterSet. The domain name appears as <service>.<ns>.svc.clusterset.local.
MCS-Controller
The MCS-Controller is an open source project that implements the multi-cluster services API specification, and is distributed under the Apache License, Version 2.0.
The MCS-Controller is a controller that syncs services across clusters, and makes them available for multi-cluster service discovery and connectivity. The implementation model is decentralized, and uses AWS Cloud Map as a registry for management and distribution of multi-cluster service data.
Note: At the time of writing this, the MCS-Controller release version is v0.3.1, which builds on key features introduced in v0.3.0 introduces new features including the ClusterProperty Central Registration Depository (CRD), as well as support for headless services. Milestones are currently in place to bring the project up to v1.0 (GA), which will include full compliance with the mcs-api specification, support for multiple AWS accounts, and AWS Cloud Map client-side traffic shaping.
AWS Cloud Map
AWS Cloud Map is a cloud resource discovery service that allows applications to discover web-based services through the AWS SDK, API calls, or Domain Name System (DNS) queries. AWS Cloud Map is a fully managed service that eliminates the need to set up, update, and manage your own service discovery tools and software.
Tutorial overview
The tutorial section of this post will take you through the end-to-end implementation of a Kubernetes multi-cluster service deployment across two Amazon Elastic Kubernetes Service (Amazon EKS) clusters, using the MCS-Controller.
The tutorial is comprised of three sections: Solution baseline, service provisioning, and service consumption. The remainder of this section will describe the objective and outcomes of each section in the tutorial.
Solution baseline
First, in the solution baseline section, we establish an environment that includes each of the dependent components required for a multi-cluster service deployment on Amazon EKS.

Image two: AWS Cloud Map MCS-Controller solution baseline overview diagram
In reference to the solution baseline diagram:
- We have two Amazon EKS clusters (cluster one and cluster two), each deployed into separate virtual private clouds (VPCs) within a single AWS Region.
- Cluster one VPC CIDR: 10.10.0.0/16, Kubernetes service IPv4 CIDR: 172.20.0.0/16.
- Cluster two VPC CIDR: 10.12.0.0/16, Kubernetes service IPv4 CIDR: 172.20.0.0/16.
- VPC peering is configured to permit network connectivity between workloads within each cluster.
- The CoreDNS multi-cluster plugin is deployed to each cluster.
- The MCS-Controller for Kubernetes is deployed to each cluster.
- Cluster one and cluster two are each configured as members of the same mcs-api
ClusterSet.- Cluster one mcs-api
ClusterSet: clusterset1,ClusterId: cls1. - Cluster two mcs-api
ClusterSet: clusterset1,ClusterId: cls2.
- Cluster one mcs-api
- Cluster one and cluster two are both provisioned with the namespace
demo. - Cluster one has a
ClusterIPservicenginx-hellodeployed to the demo namespace which frontends a x3 replica NGINX deploymentnginx-demo.- Service | nginx-hello: 172.20.150.33:80
- Endpoints | nginx-hello: 10.10.66.181:80,10.10.78.125:80,10.10.86.76:80
Service provisioning
Next, the service provisioning section will guide you through the process of making the example service available across the two Amazon EKS clusters using the MCS-Controller for Kubernetes.
With the required dependencies in place, the admin user is able to create a ServiceExport object in cluster one for the nginx-hello service. This ensures that the MCS-Controller implementation will automatically provision a corresponding ServiceImport in cluster two for consumer workloads to locate and consume the exported service.
In reference to the service provisioning diagram:
- The administrator submits the request to the cluster one Kube API server for a
ServiceExportobject to be created for ClusterIP Servicenginx-helloin the demo Namespace. - The MCS-Controller in cluster one, watching for
ServiceExportobject creation provisions a correspondingnginx-helloservice in the AWS Cloud Mapdemonamespace. The AWS Cloud Map service is provisioned with sufficient detail for the service object and corresponding EndpointSlice to be provisioned within additional clusters in theClusterSet. - The MCS-Controller in cluster two responds to the creation of the
nginx-helloAWS Cloud Map service by provisioning theServiceImportobject and correspondingEndpointSliceobjects through the Kube API Server. - The CoreDNS multi-cluster plugin, watching for
ServiceImportandEndpointSlicecreation provisions corresponding DNS records within the.clusterset.localzone.

Image three: AWS Cloud Map MCS-Controller service provisioning overview diagram
Service consumption
The service consumption section uses the example service to demonstrate the mechanics of how the MCS-Controller for Kubernetes actually facilitates the multi-cluster service discovery. The consumption process occurs across the two Amazon EKS clusters.
In reference to the service consumption diagram:
- The
client-hellopod in cluster two needs to consume thenginx-helloservice, for which all endpoints are deployed in cluster one. Theclient-hellopod requestshttp://nginx-hello.demo.svc.clusterset.local:80. DNS-based service discovery [1b] responds with the IP address of the localnginx-hello ServiceExportServiceClusterSetIP. - Requests to the local
ClusterSetIPatnginx-hello.demo.svc.clusterset.localare proxied to the endpoints located on cluster one.

Image four: AWS Cloud Map MCS-Controller service consumption overview diagram
In accordance with the mcs-api specification, a multi-cluster service will be imported by all clusters in which the service’s namespace exists. This means, each exporting cluster will also import the corresponding multi-cluster service. As such, the nginx-hello Service will also be accessible through ServiceExport Service ClusterSetIP on cluster one. Identical to cluster two, the ServiceExport Service is resolvable by name at nginx-hello.demo.svc.clusterset.local.
Tutorial
The tutorial section will guide you through the deployment and testing of the multi-cluster service implementation. As described in the tutorial overview section, this will occur across three stages: solution baseline, service provisioning, and service consumption.
Solution baseline
To prepare your environment to match the solution baseline deployment scenario, the following prerequisites should be addressed.
1. Clone the cloud-map-mcs-controller-for-k8s Git repository.
Sample configuration files will be used through the course of the tutorial, which have been made available in the cloud-map-mcs-controller repository.
Clone the repository to the host from which you will bootstrap the clusters.
All commands as provided should be run from the root directory of the cloned Git repository.
Note: Certain values located within the provided configuration files have been configured for substitution with operating system environment variables. Work instructions below will identify which environment variables should be set before issuing any commands that will rely on variable substitution.
2. Create Amazon EKS clusters.
Two Amazon EKS clusters should be provisioned, and each should be deployed into separate VPCs within a single AWS Region.
- VPCs and clusters should be provisioned with non-overlapping Classless Inter-Domain Routing or supernetting (CIDRs).
- For compatibility with the remainder of the tutorial, it is recommended that
eksctlbe used to provision the clusters and associated security configuration. By default, theeksctl createclustercommand will create a dedicated VPC.
Sample eksctl config file samples/eksctl-cluster.yaml has been provided:
- Environment variables, AWS_REGION, CLUSTER_NAME, NODEGROUP_NAME, and VPC_CIDR should be configured. Example values have been provided in the below command reference. Substitute values to suit your preference.
- Example VPC CIDRs match the values provided in the baseline configuration description.
Run the following commands to create clusters using eksctl.
Cluster one:
Cluster two:
3. Create VPC peering connection.
VPC peering is required to permit network connectivity between workloads provisioned within each cluster.
- To create the VPC peering connection, follow these instructions: Create a VPC peering connection
- VPC route tables in each VPC require updating. Read these instructions, Update your route tables for a VPC peering connection, for guidance. For a more streamlined approach, we recommend configuring route destinations as the IPv4 CIDR block of the peer VPC.
- Security groups require updating to permit cross-cluster network communication. Amazon EKS cluster security groups in each cluster should be updated to permit inbound traffic originating from external clusters. For simplicity, we recommend the cluster one and cluster two Amazon EKS security group requirements and considerations be updated to allow inbound traffic from the IPv4 CIDR block of the peer VPC.
The VPC Reachability Analyzer can be used to test and diagnose end-end connectivity between worker nodes within each cluster.
4. Activate the Amazon EKS OpenID Connect (OIDC) provider.
In order to map required AWS Cloud Map Identity Center permissions to the MCS-Controller Kubernetes service account, we need to activate the OIDC identity provider in our Amazon EKS clusters using eksctl.
- Environment variables REGION and CLUSTERNAME should be configured.
Run the following commands to activate OIDC providers using eksctl.
Cluster one:
Cluster two:
5. Implement the CoreDNS multicluster plugin.
The CoreDNS multi-cluster plugin implements the Kubernetes DNS-Based Multicluster Service Discovery Specification which allows CoreDNS to lifecycle manage DNS records for ServiceImport objects. To activate the CoreDNS multi-cluster plugin within both Amazon EKS clusters, perform the following procedure.
Update CoreDNS role-based access control (RBAC)
Run the following command against both clusters to update the system:coredns cluster role to include access to additional multi-cluster API resources:
Update the CoreDNS ConfigMap
Run the following command against both clusters to update the default CoreDNS ConfigMap to include the multi-cluster plugin directive, and clusterset.local zone:
Update the CoreDNS deployment
Run the following command against both clusters to update the default CoreDNS deployment to use the container image ghcr.io/aws/aws-cloud-map-mcs-controller-for-k8s/coredns-multicluster/coredns:v1.8.4, which includes the multi-cluster plugin:
6. Install the aws-cloud-map-mcs-controller-for-k8s.
Configure MCS-Controller RBAC
Before the AWS Cloud Map MCS-Controller is installed, we will first pre-provision the controller Service Account, granting AWS IAM Identity Center access rights AWSCloudMapFullAccess to ensure that the MCS-Controller can lifecycle manage AWS Cloud Map resources.
- Configure the environment variable CLUSTER_NAME.
Run the following commands to create the MCS-Controller namespace and service accounts in each cluster.
Change the kubectl context to the correct cluster before issuing commands.
Cluster one:
Cluster two:
Install the MCS-Controller
Next, install the MCS-Controller. Environment variable AWS_REGION should be configured.
Run the following command against both clusters to install the MCS-Controller latest release:
Assign mcs-api ClusterSet membership and Cluster identifier
To ensure that ServiceExport and ServiceImport objects propagate correctly between clusters, each cluster should be configured as a member of a single mcs-api ClusterSet (clusterset1 in our example deployment scenario). Each should also be assigned a unique mcs-api Cluster ID within the ClusterSet (cls1 and cls2 in our example deployment scenario).
- Configure the environment variable CLUSTER_ID.
- Configure the environment variable CLUSTERSET_ID
Run the following commands to configure cluster ID and ClusterSet membership:
Cluster one:
Cluster two:
7. Create nginx-hello Service.
Now that the clusters, CoreDNS, and the MCS-Controller have been configured, we can create the demo namespace in both clusters and implement the nginx-hello Service and associated Deployment into cluster one.
Run the following commands to prepare the demo environment on both clusters. Change the kubectl context to the correct cluster before issuing commands.
Cluster one:
Cluster two:
Service provisioning
With the solution baseline in place, continue to work through the service provisioning stage. First, we’ll create a ServiceExport object in cluster one for the nginx-hello Service.
This will trigger the cluster one MCS-Controller to complete service provisioning and propagation into AWS Cloud Map, and subsequent import and provisioning by the MCS-Controller in cluster two. Finally, we verify that the requisite objects have been created in cluster one, AWS Cloud Map, and cluster two.
1. Create nginx-hello ServiceExport.
Run the following command against cluster one to create the ServiceExport object for the nginx-hello Service:
2. Verify nginx-hello ServiceExport.
Let’s verify the ServiceExport creation has succeeded, and that corresponding objects have been created in cluster one, AWS Cloud Map, and cluster two.
Cluster one
When inspecting the MCS-Controller logs in cluster one, we see that the controller has detected the ServiceExport object, and created the corresponding demo namespace and nginx-hello service in AWS Cloud Map.
Using the AWS Command Line Interface (AWS CLI), we can verify namespace and service resources provisioned to AWS Cloud Map by the cluster one MCS-Controller.
Cluster two
When inspecting the MCS-Controller logs in cluster two, we see that the controller has detected the nginx-hello AWS Cloud Map service, and created the corresponding Kubernetes ServiceImport:
Inspect the cluster two Kubernetes ServiceImport object.
And the corresponding cluster two Kubernetes EndpointSlice:
It’s important to note the following:
- The
ServiceImportservice is assigned an IP address from the local Kubernetes service, IPv4 CIDR: 172.22.0.0/16 (172.20.80.119). This permits service discovery and access to the remote service endpoints from within the local cluster.
TheEndpointSliceIP addresses match those of thenginx-demoendpoints in cluster one (in other words, from the cluster one VPC CIDR: 10.10.0.0/16).
Service consumption
With the solution baseline and service provisioning in place, workloads in cluster two are now able to consume the nginx-hello service endpoints located in cluster one through the locally provisioned ServiceImport object. To complete the service consumption scenario, deploy the client-hello Pod into cluster two, and observe how it’s able to perform cross-cluster service discovery, and access each of the nginx-hello service endpoints in cluster one.
1. Create client-hello Pod.
Run the following command against the cluster two create the client-hello Pod:
2. Verify multi-cluster service consumption.
Access a command shell in the client-hello Pod, and perform an nslookup to cluster-local CoreDNS for the ServiceImport service, nginx-hello.demo.svc.clusterset.local.
Note that the Pod resolves the address of the ServiceImport object on cluster two.
Finally, generate HTTP requests from the client-hello Pod to the local nginx-hello ServiceImport service.
The responding server names and server addresses are those of the nginx-demo Pods on cluster one. Confirm that the requests to the local ClusterSetIP at nginx-hello.demo.svc.clusterset.local originating on cluster two are proxied cross-cluster to the endpoints located on cluster one.
That concludes the service consumption stage of the tutorial. You now have successfully completed the end-to-end implementation of a Kubernetes multi-cluster service deployment using the MCS-Controller.
This solution is suitable for organizations that wish to implement multiple services deployed to separate clusters, where services deployed from one cluster depend on services deployed to another cluster. This solution ensures that services in one cluster can discover services in a separate cluster (through DNS resolving to VIP), regardless of the cluster they reside in.
In addition, this solution ensures that if a dependent service is migrated between clusters, the service that depends on it is not impacted.
Conclusion
The proliferation of container adoption presents new challenges in supporting workloads that have broken through the perimeter of the single cluster construct.
For teams that want to implement a Kubernetes-centric approach to managing multi-cluster workloads, the mcs-api describes an effective approach to extending the scope of the service resource concept beyond the cluster boundary. This approach provides a mechanism to weave multiple clusters together using standard—and familiar—DNS-based service discovery.
The MCS-Controller is an open source project that integrates with AWS Cloud Map to offer a decentralized implementation of the multi-cluster services API specification. It’s particularly suited for teams looking for a lightweight and effective Kubernetes-centric mechanism to deploy multi-cluster workloads to Amazon EKS on the AWS cloud.
