Organize your AWS Serverless code to prevent merge conflicts
January 27, 2023How do you prevent the most common merge conflicts when your team is working on a Serverless application? How do you make sure that your team stays productive and avoids large merge issues while trying to update the same crucial files simultaneously? –The answer to both questions is code organization! You can use cfn-include and swagger-cli to organize, collaborate, and maintain a large serverless application as well as support a large or decentralized development team.
Real life inspiration
WRAP Technologies Inc. (WRAP) creates advanced technologies for the protection and security of public safety. Their WRAP Reality product allows law enforcement agencies to train their officers using virtual reality-based scenarios.
Too many cooks in the kitchen
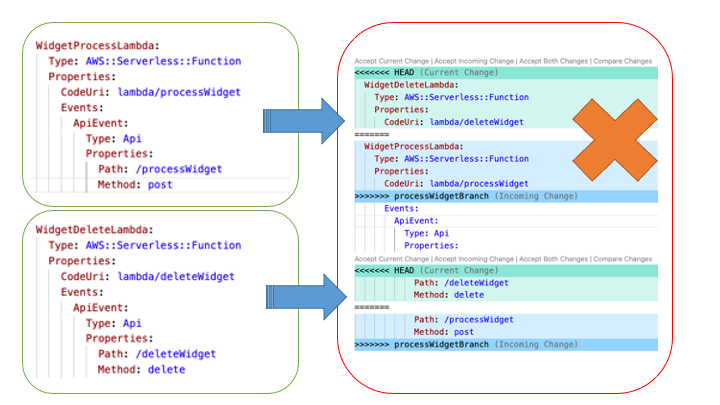
When multiple developers collaborate on a serverless architecture built with AWS CloudFormation, and its extensions such as the AWS Serverless Application Model (SAM), the nature of specifying resources in both the template.yaml and the optional OpenAPI.yaml specification for Amazon API Gateway leads to merge conflicts, such as the one demonstrated in the following figure where two developers are adding different API endpoints at the same time. These conflicts detract from the developer’s time and agility. Furthermore, navigating and maintaining the long template files required for a larger serverless architecture slows development as the developer scans large files to find a particular resource definition.

Figure 1. The frustrating merge conflicts.
By refactoring and organizing the CloudFormation and OpenAPI files, your development team can realize several benefits:
- Improve developer efficiency by decomposing large, hard-to-manage files into a series of well-organized and single-purpose files.
- Enhance developer productivity by allowing each developer to have ownership of their own code, thereby reducing the need to coordinate merges with teammates.
- Eliminate potential merge issues for files that generate the most conflicts during the development of a typical Serverless API application.
Rapid development
WRAP partnered with AWS to develop and host the backend for their new officer training management platform. This entirely new platform was developed, completed, and available for use in a matter of months. Moreover, it’s a collaboration of developers spread across multiple teams worldwide, all contributing to the same code base. By instituting the norms and techniques of this post, WRAP created a large and maintainable serverless application with minimal developer code collisions.
Development of the WRAP Reality training management system was accomplished using CloudFormation for defining Infrastructure as Code (IaC), and an Amazon API Gateway OpenAPI specification for defining API contracts. The development team for the WRAP Reality training management service leveraged agile development for expediency, including the GitHub Flow branching strategy. However, since project contributors were not co-located, several considerations were put in place to make sure of consistency and speed of code development:
- The API specifications and contracts were defined in OpenAPI (Swagger) specifications early in the development process, clearly defining the project structure up front, and allowing developers to independently build infrastructure components.
- The two code assets central to the entire project – the CloudFormation template and the OpenAPI Specification – were decomposed into small, easily manageable components. This enabled components to be organized in a way that enhanced development productivity and practically eliminated the inevitable merge conflicts that come with large source code files that are being modified on a daily basis.
The development process was accelerated by utilizing OpenAPI integrations with AWS Services, as well as techniques for managing the OpenAPI specification and Cloudformation Template files.
Sample project
To demonstrate these techniques, we’ll explore the following sample project comprised of API endpoints for “widget” management, available on GitHub. This project provides the following end points:
- /widget PUT: Creation of a new widget
- /widget GET: Retrieval of a new widget
- /reports/color GET: Retrieval of a set of widgets based on the widget color
- /reports/filterpage GET: Retrieval of widgets based on specified filters
The overall architecture of the application is shown in the following diagram:

Figure 2. Architecture Diagram
The application comprises:
- Amazon API Gateway is a fully-managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale. In this example, API Gateway serves as the web service for the API endpoints. The mapping of data to and from the API endpoints to the Lambda functions is formally defined by an OpenAPI specification file.
- AWS Lambda is a serverless compute service that lets you run code without provisioning or managing servers, creating workload-aware cluster scaling logic, maintaining event integrations, or managing runtimes. In this example, four Lambda functions are used to service each of the four API calls.
- Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. DynamoDB is used as a persistent data store for widgets and associated properties.
OpenAPI and AWS service integration
When using API Gateway, developers have the option of using proxy Lambda integrations, or formally defining the API interface in an OpenAPI yaml file. The OpenAPI specification can be leveraged to document the API prior to development, and the example/mock features of the OpenAPI specification facilitates concurrent development by quickly establishing a working infrastructure to build upon. Furthermore, API documentation can be automatically generated from the OpenAPI specification.
As the number of endpoints increases, the OpenAPI specification file can grow in size, reaching thousands of lines of code that must be updated and maintained regularly by multiple developers. To aid in management and usability, the OpenAPI file can be decomposed into separate files for endpoints, responses, fields, and schemas.
Start with a “skeleton” file as an entry point for the OpenAPI definition, and then add a separate file for the definition of each endpoint or construct. For example, the sample project entry point is api/apiSkeleton.yaml, which contains the global definitions and effectively defines a simple list of endpoints and the reference ($ref) file path to each endpoint’s definition.
The application comprises:
Diving into a file referenced by an endpoint, we see that it contains all of the specification details for that endpoint. Looking at the reportsColor.yaml file reveals the full endpoint specification for /reports/color:
In turn, this endpoint specification can include further references to yaml files defining common parameters, schemas, and even full gateway responses. For example, color.yaml defines the color path variable:
To paraphrase a common catch phrase, “With a great many files, comes a great responsibility for organization.” To this end, we offer the following organizational structure as a start. Place all of the related API specifications in an “api” subfolder of your project. Have child subfolders for field, metadata, and gateway response definition files. Then, create child subfolder trees for each branch of your endpoints that mirror the endpoint paths. This will result in a highly-organized directory structure, as seen in the sample project:
We still need a consolidated single OpenAPI file to provide to CloudFormation during deployment to AWS. Therefore, the multiple files are combined and validated using the swagger-cli bundle command, resulting in a single file for deployment. The bundle command must be executed before a CloudFormation build. This command can also be included as a shortcut in the Makefile as the “buildOpenApi” command:
or
Once compiled, api/api.yaml is then used normally for API Gateway integrations and as a Postman API Collection import. As api/api.yaml is dynamically compiled, it’s included in .gitignore and not checked in to AWS CodeCommit.
cfn-include and nested stacks
The CloudFormation template that defines the infrastructure for even a simple service can grow to considerable length, perhaps thousands of lines. This presents challenges from a support and continued development perspective, as specific code locations become difficult to find and merge conflicts become commonplace.
CloudFormation Nested Stacks are a method of breaking a large CloudFormation template into separate templates. When there are clear delineations between groups of resources in a stack breaking it into separate nested stacks makes sense. There is also a 500 resource limit in a single CloudFormation stack and in order to go above that nested or separate stacks are necessary. Depending on the complexity of the architecture and frequency of updates however, the Nested Stacks can also become large. Furthermore, in a serverless architecture, the logical separation of architecture layers into separate stacks may not be direct, for example when a Lambda function is triggered by an event sent to an EventBridge event bus, then that Lambda function sends a different event back to the same event bus.
In these cases, CloudFormation templates can be decomposed to further leverage cfn-include . With this technique, the top-level CloudFormation template becomes a skeleton file which contains the stack parameters, global specifications, a list of resource names without properties, and the outputs. The properties of each resource are contained in separate files, referenced by an ‘include’ directive.
CloudFormation template organization
To organize your CloudFormation template, deconstruct the template into one-file-per-resource, with one main “skeleton” file as the main entry point. This skeleton file contains the full parameters, global section, conditions, and output specification. The resources are specified by resource name in this skeleton file, and then an ‘include’ directive points to the file that contains the body of the resource declaration. See the following example of the main skeleton file with two resources:
Then, the resource files contain the properties of that specific resource. For example, widgetApiGW.yaml defines an API Gateway:
This approach has the benefit of breaking the CloudFormation template into multiple small files, while still maintaining a top-level holistic view. The resource definitions, which normally comprise the majority of the content and can cause merge conflicts, are moved out of the main template.
For organization, you can create a directory in your project to contain the CloudFormation scripts. This directory also contains the entry-point skeleton file. Create further sub-folders for resources, and then further folders by resource type and architecture. We found that placing applicable AWS Identity and Access Management (IAM) role resource definitions in the same folder with the applied resource facilitated easier navigation. For example:
The files must be reconstituted to a single template.yaml for CloudFormation build and deployment. This is accomplished with the cfn-include command. A convenience command can optionally be included in the Makefile.
or
As the final template.yaml file is dynamically compiled, it’s included in .gitignore and not checked in to CodeCommit.
Conclusion
This post demonstrates techniques used by WRAP and AWS to rapidly develop and maintain key files in an Serverless architecture. The techniques discussed in this post allowed the WRAP and AWS team to do the following:
- Improve developer efficiency by decomposing large, hard-to-manage files into a series of well-organized and single purpose files.
- Enhance developer productivity by allowing each developer to have ownership of their own piece of the code without having to coordinate with teammates.
- Eliminate potential merge issues on the files that typically generate the most conflicts during the development of a typical Serverless API application.
Applying these techniques was one of the key factors in the rapid development of the WRAP Reality training framework.
About the Authors:
